Note: This manual applies to the Neuroplayer 166+ with LWDAQ 10.6.2+.
Note: Video playback supported on Windows, MacOS, Ubuntu, and Raspberry Pi.
Warning: The Neuroplayer assumes there are no spaces in any directory or file names.
[02-OCT-23] The Neuroplayer is a component of our LWDAQ Software. It provides a suit of functions for use with recordings made from Subcutaneous Transmitters (SCT) using a separate component of the software called the Neurorecorder. The Neuroplayer reads signals from disk, displays signals, and performs processing and analysis. Analsysis includes event detection and real-time event handling. For a video introduction the Neurorecorder and Neuroplayer, see here.
When we select Neuroplayer in the Tool Menu, the Neuroplayer runs in its own, separate process. If the Neuroplayer crashes, no other process will be stopped or slowed down. Each time we select Neuroplayer in the Tool Menu, we create a new Neuroplayer. With multiple Neuroplayers, we can analyze multiple recordings simultaneously and independently on the same computer.

The Neuroplayer provides display of signals, display of video, export to other file formats, analysis, event detection, and real-time event response.
The Neuroplayer can read the archive that is being recorded, as it is recorded, or it can read a different archive. The Activity list shows the transmitter channels present in the playback interval. Each channel number is followed by a colon and the number of messages from this channel in the raw data. A transmitter running at 512 MSP will provide up to 512 messages in a 1-s interval. In the picture, the Processor is enabled. The processing script will be applied to each playback interval and its result printed in the text window. These lines are not currently being saved to disk, however, because the Save button is not checked.

The Value vs. Time plot shows the signal voltages during the playback interval. The plot can be simple, centered, or normalized. The Amplitude vs. Frequency plot shows the spectrum of the signals during the playback interval. We choose which channels will be plotted, transformed, and processed with the processor selection string, which is available in the Neuroplayer's Select field. The string "1 2 3 78" would select channels 1, 2, 3, and 78 only. An asterisk (*) selects all available channels. We discuss channel selection in more detail below. Even the results of processing, shown in the text window, are restricted to the selected channels.
The Neuroplayer state is Play. A yellow background means the Neuroplayer is waiting for more data to be written to the play file, which occurs when we are playing a file as it is being recorded. A green background means that the Neuroplayer is processing signals. When the orange background appears behind the Neuroplayer state, the Neuroplayer is jumping to a new archive or to a new point within an archive.
The Configure button opens the a Configuration Panel, which contains configuration parameters for the Neuroplayer. When you press Save Configuration, the Neuroplayer saves all its configuration parameters in the LWDAQ/Tools/Data folder. When you next open the Neuroplayer, all these settings will once again be loaded into the tool. All Neuroplayers share the same settings file, so we cannot save and recall the distinct settings of multiple Neuroplayers. When you press Unsave Configuration, the Neuroplayer deletes any existing settings file.
Follow our Subcutaneous Transmitter (SCT) set-up instructions to get your data receiver and computer communicating with one another. As part of the set-up you will download and install the LWDAQ Software. To record signals to disk, select the Neurorecorder from the Tool Menu and follow the setup instructions in the Neurorecorder manual. To play back and process existing archives, select the Neuroplayer in the Tool Menu and follow the instructions below.
Press Pick on the Archive row and select the archive being written to by the Neurorecorder. Press Play. The Neuroplayer state will flash green when it extracts a new interval, and yellow when it is waiting for new data. Look at your data receiver. The EMPTY light should be flashing regularly. If it is not flashing, your Neurorecorder is not acquiring data as fast as the data is being generated. A failure to keep up with the pace of recording can be arise in several ways. Your network could be interrupted, your computer could be performing an update to its operating system, or video recording could be over-working the network. Once you get the recording and playback working, you can try out various values of playback interval. You can look through previously-recorded archives even while you are recording a new archive. Stop the simultaneous playback and select a new archive. If you want to see an overview of an entire archive, select it in the Neuroplayer and press the Overview button. If you double-click on the Overview, the Neuroplayer will find the time you clicked and show you it in detail.
The Neuroplayer will continue past the end of an archive if you have play_stop_at_end set to zero, which is the default. You will find this parameter in the Configuration Panel. When the Neuroplayer reaches the end of an archive, it will make a list of all the NDF archives in its directory tree, and find the next file after the current file to continue playback. If you set play_stop_at_end to one, the Neuroplayer will stop at the end of its file. You specify the Neuroplayer's directory tree with the PickDir button. Select the top directory in the tree.
When our telemetry system consists of several data receivers, we will need one Neurorecorder for each. If we want to process the signals as they are recorded, we will need at least one Neuroplayer per receiver. We may even need one Neuroplayer per animal. For example, we may have two animal location trackers (ALTs) with four animals over each tracker, and we want to export the signals from each animal to separate EDF files. We need two Neurorecorders and eight Neuroplayers. The Startup Manager allows us to define our telemetry recording and processing with a script and start all processes by running the script. After an interruption, we can re-start the system with a few mouse clicks.
The Neuroplayer draws two plots during playback. On the left is value versus time, or VT. On the right is amplitude versus frequency, or AF. Each plot has its own Enable flag. Disable the plots if you want processing to proceed as fast as possible. When the plots are disabled, they will be blank. The VT plot shows the signal during the most recent playback interval. The AF plot shows its frequency spectrum as obtained by a discrete Fourier transform (DFT). Double-click on either plot and a new double-size version will open up with its own control buttons. The traces in both plots are color-coded by recording channel number. For a picture of all the channel colors marked with their channel numbers, see Receiver Colors.
By default, the Neuroplayer uses the color coding shown above, which is the default LWDAQ color scheme for numbered plots. In the Activity Panel, we can click and change the color used for each channel individually. We click until we get a color we like. The Activity Panel assigns new colors using Neuroplayer's color_table. Each entry in the color table is a channel number and a number that selects a color from the default color coding. If we want to pick colors, we can edit the color table string in the Configuration Panel.
Example: The color_table string is by default "{0 0}", just to show us the format of its elements. But if we change it to "{5 7} {9 2} {222 1}" the trace for channel five will have color seven (salmon), for channel nine will have color two (blue), and for channel two hundred and twenty three will have color one (green).
Before the Neuroplayer generates the VT and AF plots, it applies signal reconstruction and glitch filtering to the signal. The glitch filter threshold appears below the plot. We disable the glitch filter by entering 0 for the threshold. We turn off signal reconstruction by setting the enable_reconstruct to zero. With reconstruction disabled, missing messages will remain missing.
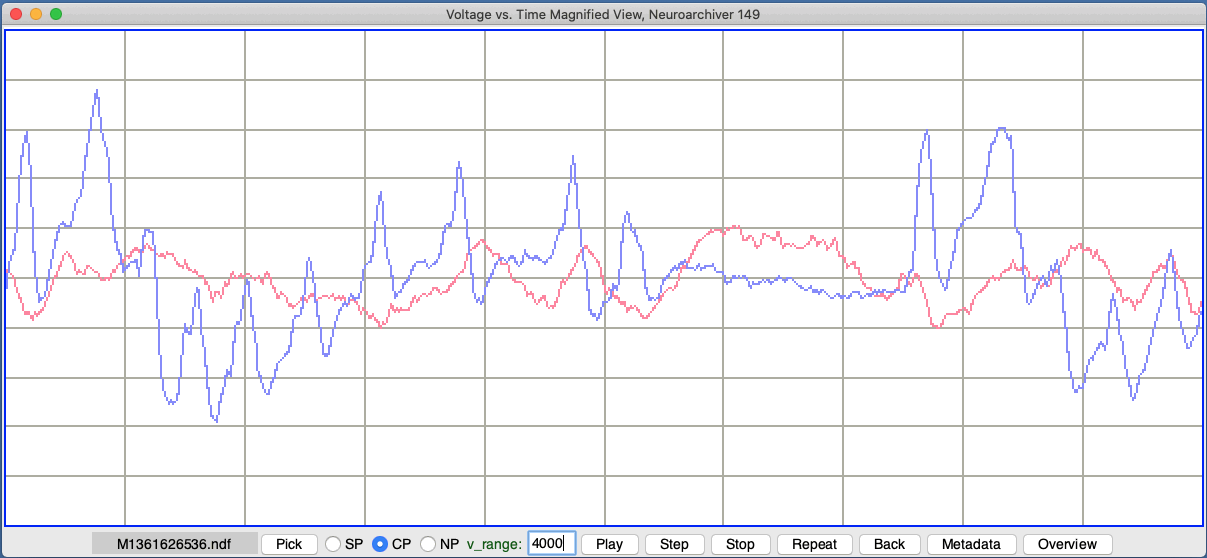
The VT plot shows signal voltage versus time. The vertical axis is voltage in ADC counts. Each transmitter converts its analog input into a sixteen-bit value. Sixteen-bit values run from 0 to 65535. We consult the transmitter's manual to obtain its nominal conversion factor. The actual conversion factor will be 5% higher at the beginning of the transmitter's life, and 5% less towards the end of its life.
Example: The A3028 version table gives nominal conversion factors for all versions of the A3028 subcutaneous transmitter. The conversion factor for the two inputs of the A3028A is 0.41 μV/cnt (microvolts per count). If we set v_range to to 2440 and apply alternating coupling, the height of the display represents 1 mV. With a one-second playback interval, each of the ten horizontal divisions is 100 ms.
There are three ways to plot scale the VT voltage values. In simple plot we select with the SP button. The v_range value sets the range of the plot from bottom to top in ADC counts. The v_offset sets the voltage at the bottom of the display. The centered plot uses v_range in the same way, but ignores v_offset. The plot of each signal is centered upon the window, so that the average value of the signal is exactly half-way up. The normalized plot ignores both v_range and v_offset and fits the signal exactly into the height of the display. We disable the voltage and time grid in a normalized plot, both to serve as a warning that the vertical scale is normalized, and to allow a clearer view of signal details.
The horizontal axis in the VT plot is time. The t_min value is the time at the left edge of the interval. The full range from left to right covers the most recent playback interval. This interval is shown in the Interval menu button beneath the plots. Note that the playback time, in the Time (s) entry box, is the time at which the next playback interval should begin. During continuous playback, this will be the time at the right edge of the plot.
The AF plot shows the amplitudes of the signal spectrum versus frequency. The amplitude is the maximum deviation of each sinusoidal component from zero, which is one half the peak-to-peak amplitude, and √2 times the root mean square amplitude. We calculate the spectrum with the discrete Fourier transform. The transform amplitude range is a_min to a_max, both in units of ADC counts. The Neuroplayer calculates all terms in the discrete Fourier transform and plots those between f_min to f_max. The discrete Fourier transform dictates a particular frequency step from one discrete component to the next. We have f_step = 1/p, where p is the playback interval. The highest frequency component in the transform is at half the transmitter's message frequency. For a 512-SPS transmitter, the highest frequency component in the transform will be 256 Hz. If we set the range of the frequency plot outside the range zero to one half the sampling frequency, the spectrum will be blank. Note that the transform applies to the reconstructed and glitch-filtered signal.
Detail: The reconstructed signal will always contain messages at exactly the transmitter's nominal frequency, regardless of how many messages were lost. We calculate the transform using an fast Fourier transform algorithm. This algorithm requires a perfect power of two number of samples as its input, in order to allow its divide and conquer method to operate with perfect symmetry upon the problem. All our transmitters operate at a frequency that is a perfect power of two, so choosing playback intervals that are a power-of-two fractions of multiples of one second will always give us a number of samples that satisfies our algorithm. It is possible to turn off reconstruction in the Neuroplayer by setting enable_reconstruct to 0. If we turn off reconstruction, the Neuroplayer will add dummy messages or subtract excess messages before calculating the spectrum. See the Receiver Instrument manual for more details.
Example: With amplitude range 1000 counts, each vertical division is 100 counts. Suppose our sample rate is 512 SPS. We set f_min to 0 Hz and f_max to 256 Hz so that we can see the entire discrete Fourier transform of the 512 samples taken in the 1-s play interval. The frequency step is 1 Hz because the play interval is 1 s. If we switch the play interval to 4 s, the frequency step will change to 0.25 s.
If we click the Log checkbox, the frequency axis will become logarithmic, with lines marking the decades in the traditional fashion.
Detail: We do not provide logarithmic display for the amplitude, although we could easily do so. The logarithmic frequency display is not particularly useful because the Fourier transform components are distributed in uniform frequency steps instead of logarithmic steps.
We describe the generation and adjustment of the frequency spectrum in more detail below.
Warning: Do not use white spaces in your directory names or file names. Use underscores or dashes instead.
The Neuroplayer displays the names of three files: the playback archive, the processing script, and the event list. It also allows us to pick a directory in which video files are stored. We can select these files using the Pick buttons beside each file name. The Neuroplayer looks for archives to play or jump to in the directory tree you specify with its PickDir button. You pick a directory and the Neuroplayer will make a list of all archives in this directory and its sub-directories.
The Neurorecorder stores transmitter messages in NDF (Neuroscience Data Format) files. It performs no processing upon the messages as it stores them to disk. What appears in the NDF file is exactly the same sequence of messages that the Data Receiver stored it its memory. Thus we have the raw data on disk, and no information is lost in the storage process. An NDF file contains a header, metadata string, and a data block to which we can append data at any time without writing to the header or the data string. We define the NDF format in the Images section of the LWDAQ Manual. We describe how SCT messages are stored in the data section of NDF files in Reading NDF Files. The Neuroplayer manipulates NDF files with a NDF-handling routines provided by LWDAQ. These routines are declared in LWDAQ's Utils.tcl script. You will find them described in the LWDAQ Command Reference. Their names begin with LWDAQ_ndf_.
All archives created by the Neurorecorder receive a name of the form Mx.ndf, where M is a prefix set by the Neurorecorder's ndf_prefix parameter. The default value of ndf_prefix is "M", so almost all NDF file names start with the letter "M". The ten-digit number specifies standard Unix Time. The ten-digit number is the number of seconds since time 00:00 hours on 1st January 1970, GMT. We get the Unix time in a Tcl script with command clock seconds. From the name of each file, we can determine the time, to within a second, at which its first clock message occurred. From there we can count clock messages and determine the time at which any other part of the data occurred. The Neuroplayer's Clock Panel, which we open with the Clock button, uses the timestamps in NDF file names to find intervals corresponding to specified absolute times.
The Neuroplayer reads the NDF archives to extract voltages and calculate spectra. When the Neuroplayer reaches the end of an archive, it looks for a newer archive in the same directory and starts playing that one immediately afterwards. Thus if we are playing the archive that is being recorded, the Neuroplayer will play the fresh data from the expanding archive until the Neurorecorder starts a new archive, at which time the Neuroplayer will switch to the new archive automatically. If we are playing old archives, the Neuroplayer will still move from the end of one to the start of the next, even if the next is unrelated to the first. Thus we can go through a collection of archives that are from different experiments and different times, and apply processing to extract characteristics from all the archives.
The Neuroplayer provides a Metadata button. This button opens up a text window that displays the metadata of the playback archive and allows us to add comments and save the metadata to disk. The comments in an archive's metadata can remind us of what the file contains. The generic names of our archives don't help much when it comes to identifying particular experiments. So the Neuroplayer provides a List button that allows us to choose files in a single directory whose metadata comments we wish to inspect.
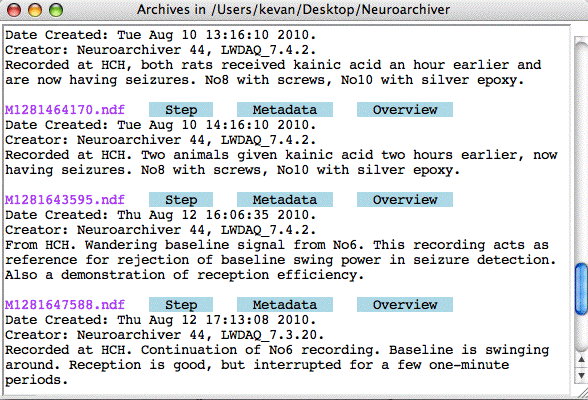
When we press the List button, the Neuroplayer will ask us to specify one or more files in a single directory. It will open a new window and display these archives with their metadata comments. The list window provides three buttons for each archive: Step, Metadata, and Overview. These allow us to step directly into the start on an archive, edit the metadata, or jump to an overview of its contents.
The Neuroplayer's video playback uses video files in mp4 containers whose names are in the form Vx.mp4, where x is a Unix Time. The video file itself can be in any standard format, but they must contain key frames at the start of every whole second, which is not the case for standard video camera recordings. Use our Animal Cage Cameras to obtain video suitable for use with the Neuroplayer.
The Neuroplayer works with two classes of text files. The first are Processing Scripts. These are TclTk programs that the Neuroplayer will apply to the signals in each playback interval. The second are Event Lists. These are lists of events detected in recorded signals that the Neuroplayer uses to navigate between events. We select these files with Pick buttons. We can read, edit, and save such files with LWDAQ's built-in Script Editor, available in the Tool Menu.
When playback or processing generates a warning or an error, these appear in the text window in blue and red respectively. If we set log_warnings to 1, the Neuroplayer will write all warnings and errors to a log file. The name of the log file is stored in log_file. By default, the log file is the /Tools/Data directory and is named Neuroplayer_log.txt. We can change the name of the log file and so place it somewhere else. The warnings and error messages all include the current time as a suffix, which is the time the Neuroplayer discovered a problem. The warnings that mention the name of an NDF file contain the playback time at which the problem was encountered.
Channel selection is supported by the Neuroplayer through its processor select string, available in the Select field. In its simplest form, the processor select string is a single "*", or "wildcard", character. With the wildcard string, the Neuroplayer looks through the playback interval data and counts how many messages it contains from each of the possible subcutaneous transmitter channel numbers. If we have more than activity_threshold samples per second in any channel, the Neuroplayer considers it active. With the wildcard selection, the Neuroplayer plots all active channels and lists them in the Neuroplayer's Activity string. The activity list has format id:qty, where id is the channel number and qty is the number of messages. When we have many active channels, we use the Activity Panel to view all of them, their sample rates, and plot colors.
We can select particular channels with a specific channel_select string. We can enter "1 2 6 14 217 222" and the Neuroplayer will attempt to display these channels, even if they have very few messages. We can specify the nominal sampling frequency for each channel. If we want to specify the frequency, we do so with two numbers in the form c:f. Thus "5:1024" means channel 5 with sampling frequency 1024 SPS. When we press the Neuroplayer's Autofill button, the Neuroplayer re-plays the most recent second of the playback archive, looks for active channel numbers, guesses their sample rates, and fills in the channel_select string for us. Most often, autofill will work fine, but check the result to make sure all your transmitters are included, and the sample rates are correct. For more on sampling frequency see the Receiver Instrument manual.
If we list the channel numbers on their own, or if we use "*" to specify all channels, the Neuroplayer uses the default_frequency parameter to determine the sample frequency. The default frequency can be one value, such as "512", or a list of values, such as "128 256 512 1024 2048 4096". If it is a list, the Neuroplayer will try to pick the best match between the data and the frequencies in the list. Thus we can, provided reception is better than 80%, detect automatically sample rates of 128, 256, 512, 1024, 2048, and 4096 SPS.
The sampling frequency is used by the Neuroplayer when it reconstructs an incoming message stream. The Neuroplayer uses its clocks_per_second and ticks_per_clock parameter to convert samples per second into a sample period in units of data recorder clock ticks. The Neuroplayer can then go through a channel's messages and identify places where messages are missing, and eliminate bad messages that occur in the message stream at random times.
By default, the Neuroplayer applies reconstruction to all data during playback. But we can disable the reconstruction by setting enable_reconstruct to zero in the configuration array. We sometimes disable reconstruction so we can get a better look at bad messages and other reception problems.
The NDF format contains a header, a metadata string, and a data block. Transmitter messages and clock messages are stored by the Neurorecorder in the data block. New data is appended to the data block without any alteration of existing data. The metadata string has a fixed space allocated to it in the file, but is itself of variable length, being a null-terminated string of characters. We can edit the metadata of the playback archive with the Metadata button. We can save baseline powers to the playback archive metadata with the Save to Metadata button in the Calibration Panel. At the top of the metadata there is a metadata header, which the Neurorecorder writes into the metadata when it creates the recording archive. The metadata header contains one or two comment fields, where one comment is a string delimited by an xml "c" tags, like this:
<c> Date Created: 17-Jun-2021 14:29:09. Creator: Neurorecorder 145, LWDAQ_10.2.10. </c> <payload>16</payload> <coordinates>0 0 0 12 0 24 12 0 12 12 12 24 24 0 24 12 24 24 36 0 36 12 36 24 48 0 48 12 48 24</coordinates>
The Neurorecorder always generates a header comment like the one shown above. It also writes the message payload and tracker coil locations to the metadata so that subsequent playback of archives recorded from various data receivers will be configured by the metadata automatically. When we edit and save the metadata of a playback archive, the Neuroplayer does not add "c" tags to our edits. This allows us to add any other type of field we like. We can ensure that the Neuroplayer will recognize our edits as comments by including our text in fields delimited by "c" tags. The List button opens a List Window. The List Window that provides us with a print-out of the comments from a selection of files. Thus we can use metadata comments to describe the contents and origin of our archives, and then view these comments later.
The Neuroplayer performs all its signal reconstruction and plotting when it reads data from disk. Each plot has its own enable checkbox. If we want the Neuroplayer to calculate interval characteristics with a processing script, we can accelerate the processing by turning off the plots. If we check the Verbose box, the Neuroplayer will report on its reading and processing of data. We will see the loss in each channel, and the results of reconstruction and extraction of message from the playback interval's data.
When we open a new archive, the Neuroplayer calculates the length of time spanned by the recording the archive contains. If the recording is one hour long, "3600.0" should appear for "End (s)". We can navigate through the playback archive by entering a new Time value and pressing Step. The Play button starts moving through an archive, one interval at a time. We can slow down playback by setting the Slow flag. The Neuroplayer will wait slow_play_ms milliseconds before displaying the next interval. By default, the delay is one second, but you can set it to any value you like.
When the Neuroplayer reaches the end of the file, it will continue to the next archive in the Neuroplayer's directory tree, unless you set player_stop_at_end to 1. By "next archive" mean the file after the current file in the alphabetical list of all NDF files in the Neuroplayer's directory tree. If we are playing data as it is recorded, we will want the Neuroplayer to wait until new data is recorded in the playback archive, unless the Neurorecorder has created a new archive, in which case the Neuroplayer should move on to the new one. This progression will occur automatically provided that the Neuroplayer's directory tree contains no archives with names that follow alphabetically after the current playback archive. This is sure to be the case if all files are named Mx.ndf, where x is a UNIX timestamp giving the start time of the recording. But if the files have other names, perhaps because they have been imported from other formats, or do make their names more descriptive, the Neuroplayer may start playing an entirely unrelated and older file after it finishes the current play file.
The Stop button stops Play. The Repeat button causes the Neuroplayer repeat the processing and display of the current playback interval. We use the Repeat button when we change the plot ranges or processing script so as to re-display and re-calculate characteristics of the same interval. The Back button step back one playback interval. The Reload button loads the file as if for the first time, and plays the first interval. If we edit the file's metadata, theReload button will assert the new tracker coordinates and background powers we wrote to the metadata.
The Neuroplayer recognizes several key stroke commands. We activate these with the Command key on MacOS, the Alt key on Windows, and the Control key on Linux. Command-right-arrow performs the Step function. Command-left-arrow is Back. Command-up-arrow jumps to the start of the next archive in the playback directory tree. Command-down-arrow jumps to the start of the previous archive. Command-greater-than (shift-period on a US keyboard) is Play. Command-less-than (shift-comma on a US keyboard) jumps back to the start of the archive. The same command keys apply in the magnified views of the signal and spectrum plots.
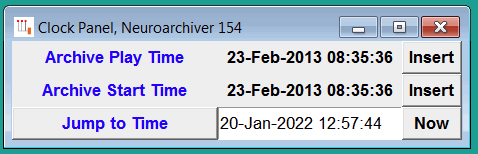
The Clock button opens the Clock Panel. The Clock Panel displays the current play time as an absolute date and time, and the start time of the current play file as an absolute date and time also. The Jump to Time button jumps the Neuroplayer to the absolute date and time we specify. To determine the absolute date and time of a recording interval, the Neuroplayer assumes all archives are named Mx.ndf, where x is the UNIX timestamp of the start of the recording. We set the Jump to Time value to the current local time with the Now button. We set it to the play file's start time or the current play time with the corresponding Insert buttons.
When the Neuroplayer calculates the length of the archive, and navigates to particular points in the archiver, it uses one of two algorithms. The default algorithm is non-sequential. The non-sequential algorithm is quick to calculate archive time, even with the largest archives. If your archive is corrupted, as it might be following interruption of data acquisition, the non-sequential algorithm will fail because the clock messages in the recording are no longer accurate. For corrupted archives, we use the sequential algorithm. The sequential algorithm is is far slower when navigating between locations in an archive, but gives unambiguous time values for even the most corrupted archives. Select sequential navigation with the Sequential flag. When we already know the time and location of the start of an interval, the sequential algorithm is more efficient and it is always robust. When the Neuroplayer plays through an archive, going from one interval to the next, it always uses the sequential navigation algorithm, regardless of the Sequential flag.
If we want to move from one event to another within or between archives, we can use an event list. The Neuroplayer provides Next, Go, and Previous buttons, as well as an event index, to allow us to navigate through an event list.
Subcutaneous transmitter recordings contain occasional glitches caused by bad messages. When a bad message occurs during a sample window in which the real sample has gone missing, the bad message will be accepted into the signal. If further samples are missing immediately after, this same bad message will be used to fill in for the missing messages. Thus glitches are either one-sample spikes or they are spikes with several equal samples at the top or bottom. The glitch filter attempts to remove such glitches by looking for jumps in the signal that exceed the Neuroplayer's glitch threshold, and checking to see if there is another jump that exceeds the threshold in the opposite direction immediately after, or if the next sample is identical. The probability of two samples being identical in physiological telemetry signal are small.
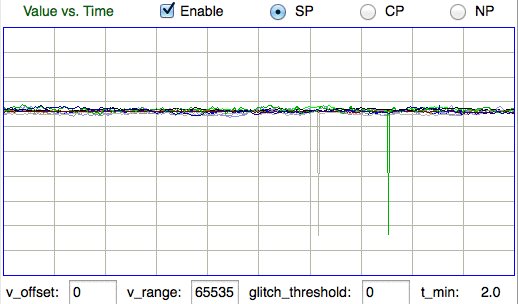
The glitch filter uses the glitch_threshold displayed below the VT plot. The units of threshold are sixteen-bit ADC counts. To disable the glitch filter, enter zero for the glitch threshold. The Neuroplayer calls the glitch filter just after reconstruction. If reconstruction is disabled by setting enable_reconstruction to zero, the Neuroplayer extracts the available samples and does not apply the glitch filter.
With glitch_threshold = 1000, we observe several glitches per hour from implanted A3028B transmitters in faraday enclosures. Outside a faraday enclosure, when reception is poor, the rate is several glitches per minute. The Neuroplayer keeps count of the number of glitches it has removed in the glitch_count parameter, which is visible in the Configuration Panel.
A useful glitch filter will leave real, spike-like features in our signals intact. In EEG recordings, we want the glitch filter to remove artifacts of telemetry but leave intact our recording of inter-ictal spikes. The sharpest inter-ictal spikes we have seen in were those we recorded in this study, of which we present several examples below.
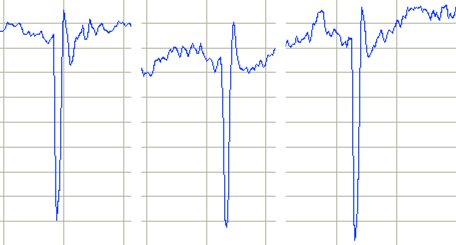
These spikes are only 20-ms long, have typical amplitude 600 μV, but can be as large as 1600 μV. We applied the glitch filter with various thresholds to one hundred such spikes. Some were affected slightly with threshold 500 (200 μV). None were affected by a threshold of 1000. These being the most demanding spikes for the glitch threshold to avoid attenuating, we set the default value of the glitch threshold to 500.
The Overview button opens in a separate window and plots an entire archive. The Neuroplayer does not plot all messages in the archive. It picks overview_num_samples messages distributed evenly throughout the archive, taken from the channels specified by the processing select string. There is some randomness in the choice of points, so the plot will not exhibit distortion by aliasing. The result is a plot that gives a good representation of the archive contents, but not an exact representation. And each time we re-plot the archive, we will see slightly different peaks. The overview applies a glitch filter to its overview plot. It uses the same glitch threshold we have defined for interval playback.
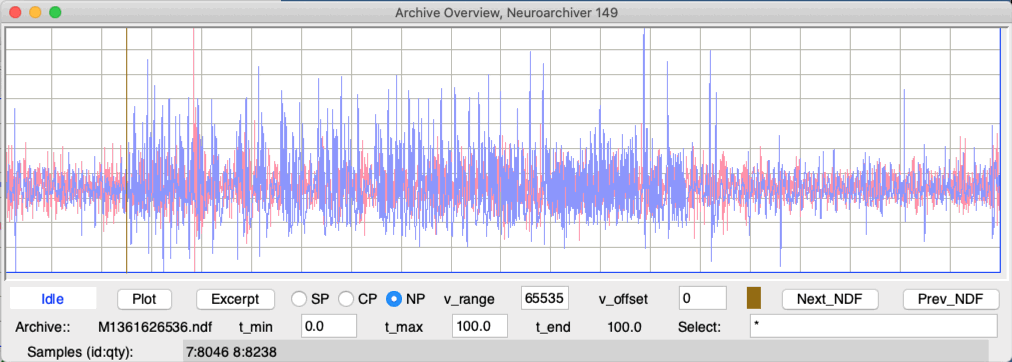
The Overview provides time and voltage controls with which we can define a new overview plot. The Overview will not refresh until we press Plot. The time controls allow us to define a sub-range of the archive. The Excerpt button creates a new NDF file containing the recorded data in the range t_min to t_max inclusive. The metadata of the excerpt file will be copied from the original archive's metadata. The new file will begin with the letter "X" and contain the UNIX time of the first second of the recording it contains.
Detail: Clock messages are embedded in the received message stream. They have the same format as sample messages, with channel identifier zero. By default, we do not display or process channel zero, but if we write a zero into the processor select string, the clock messages will appear in the overview as a ramp with 128 SPS and period 512 s.
When the Overview shows the playback archive, it marks the play time with a thin vertical line, which we call the overview cursor. The cursor color is shown in a little box below the plot. We change the cursor color by clicking the box until we reach a color we like. With the Overview open during playback, we will see the cursor moving slowly to the right. If we double-click on a point in the overview, the Neuroplayer will jump to that point, and the cursor will move there too.
The NextNDF PrevNDF buttons allow us to switch to the next or previous archive in the Neuroplayer's directory tree. We can also obtain archive overviews from List windows generated with the Neuroplayer's List button. If the archive shown in the overview is not the same as the playback archive, no cursor will be drawn in the overview. When we jump to a location in the overview, however, the Neuroplayer will switch to the overview archive and draw the cursor.
We calculate the discrete Fourier transform of each channel using our lwdaq_fft routine, which is available in the LWDAQ command line. The lwdaq_fft routine takes the sequence of sample values produced by reconstruction and returns the complete discrete Fourier transform. If we pass N terms to the transform, we get N/2 terms back. The lwdaq_fft routine uses the fast Fourier transform calculation, which is a divide and conquer algorithm that insists upon a number of samples that is an integer power of two. We can pass it 16, 32, 256, 512, or 1024 samples. Signal reconstruction ensures that we have a suitable number of samples. If we turn off reconstruction by setting enable_reconstruct to zero, the Neuroplayer adds or subtracts samples to or from the signal so as to satisfy the Fourier transform's requirements.
When a signal's end value differs greatly from its start value, the Fourier transform sees a sharp step at the end of what it assumes is a periodic function represented by the signal interval. Such a step generates power at all frequencies of the spectrum, rendering the spectrum less useful for detecting events such as epileptic seizures. The Neuroplayer applies a window function to the signal before it applies the Fourier transform. The window_fraction element in the Neuroplayer's configuration array gives the fraction of the signal that should be subject to the window-function at the start and at the end of the sequence of available samples. We like to use window_fraction 0.1 for EEG (electroencephalograph) signals. The window function is provided as an option in the lwdaq_fft routine.
Data from wireless transmitters can contain bad messages arising from interference and noise. Signal reconstruction attempts to eliminate these messages, but we can still get several bad messages per hour on each signal channel, and these appear as one-sample spikes. The Neuroplayer uses its glitch filter to remove such spikes immediately after signal reconstruction. We can analyze and manipulate the spectrum of the signal with interval processing, using the info(signal) array.
In each playback step, the Neuroplayer goes through each channel selected by channel_select and performs reconstruction, glitch filtering, spectrum-calculation, plotting, and processing. We enable processing with the enable processing checkbox. The processing reads the processor from disk. The processor must be a proper TclTk script. The Neuroplayer executes the script once for each selected channel.
If you want to learn how to program in TclTk, so that you can write your own processors, we recommend Practical Programming in TclTk. Otherwise, you can consult About TclTk and the TclTk Manual. The language is interpreted rather than compiled, and the interpreter is available on all operating systems. Thus our LWDAQ software, and any scripts you write in TclTk, will work in MacOS, Windows, and Linux equally well.
The processing script has access to the Neuroplayer's configuration and information arrays with the config(element_name) and info(element_name) respectively. The configuration parameters are ones the user is free to modify. The info parameters are a mixture of parameters that are too numerous to list in the configuration array and others that the user should not change. The processing script also has access to several temporary variables. We list some of the most useful variables in the following table.
| Variable | Contents |
|---|---|
| num_clocks | The number of clock messages in the current playback interval |
| result | The processing results string, integers are always channel numbers |
| config(play_file) | The NDF archive being played back |
| config(play_time) | Seconds from archive start to interval start |
| config(enable_vt) | Voltage-time display is enabled |
| config(processor_file) | The processing script file |
| config(channel_select) | The channel-selection string, if * then all channels chosen |
| config(play_interval) | The playback interval in seconds |
| info(channel_num) | The number of the channel just reconstructed and transformed |
| info(num_received) | The number of messages received in this channel during this interval |
| info(num_messages) | The number of messages in the reconstructed signal |
| info(loss) | The signal loss as a percentage. Subtract from 100% to obtain reception efficiency. |
| info(signal) | The reconstructed signal as sequence of timestamps and values |
| info(spectrum) | The transform as sequence of amplitudes and phases |
| info(f_step) | The separation in Hertz of the transform components, equal 1/play_interval |
| info(bp_n) | The baseline power of channel n |
| info(f_n) | The sampling frequency assumed for a channel n |
| info(num_errors) | The number of data corruptions present in this interval |
| info(tracker_history) | The history of locations for the current channel. |
| info(tracker_x) | The tracker x-coordinate of the current channel. |
| info(tracker_y) | The tracker y-coordinate of the current channel. |
| info(tracker_powers) | The median tracker coil powers for the current channel. |
The characteristics are stored in the result string. Any word or number can be added to the characteristics of each channel, except that only channel numbers may be written to the string as integers. Subsequent analysis is able to separate the characteristics of the various channels by looking for the integers that delimit the channel data. If we want to store a value 4 as a characteristic, we can write it as 4.0.
Other elements of the configuration array we can find by pressing the Configure button in the Neuroplayer window. Each is available with config(element_name) in the processing script. The information array elements we will have to seek out at the top of the Neuroplayer script itself, where each is described in the comments.
If we select four channels for playback, the processing script will be called four times. Each time the Neuroplayer calls the script, all variables that are specific to individual channels, such as loss, num_received, signal and spectrum, will be set for the current channel. We obtain the current channel number through the channel_num parameter.
The first time the processing is called, the result string is empty. Each call to the processing should append some more values to the result string. After the final call to the processing script, if the Neuroplayer sees that result is not an empty string, it prints it to the text window. If the Save box is checked, it appends the string to the a characteristics file. The name of the characteristics file will be a combination of the archive and processor names. If the archive is M1234567890.ndf and the processor is Processor.tcl, the characteristics file will be M1234567890_Processor.txt. The Neuroplayer will look for the characteristics file in the same directory as the processor script. If it does not find the file, it will create the file. If it finds the file, it will append the latest interval characteristics to the existing file. The Neuroplayer will never delete the file or over-write any lines in the file.
The following script records the reception efficiency for each active channel. This allows us to plot message reception versus time by importing the characteristics file into a spreadsheet.
append result "$info(channel_num) [format %.2f [expr 100.0 - $info(loss)]] "
Once the analysis has been applied to all active channels, the Neuroplayer checks the result string. If the string is not empty, the Neuroplayer adds the name of the play file and the play time to the beginning of the string. These two pieces of information apply equally to all channels, and are essential characteristics for event detection.
Because the script is TclTk, it can do just about anything that TclTk can do. In theory, it can e-mail the finished result string to us, or upload it over the network to a server. Most processor scripts produce characteristics files through use of the result string. But we can also use processing to export signals or spectra to disk.
The reconstructed signal is available in info(signal). The signal takes the form of a sequence of numbers separated by spaces. Each pair of numbers is the time and value of the signal. The time is in clock ticks from the start of the playback interval. The value is in sixteen-bit ADC counts. The timestamps are twenty-four bit numbers that give the number of data receiver ticks since the start of the playback interval. A twenty-four bit number is up to 16.8 million, and the tick frequency in the A3018 data receiver is 32.768 kHz. The maximum interval we can cover with these timestamps is 512 seconds. We usually specify intervals between 0.1 and 10 s. The sample values are sixteen-bit un-signed numbers.
The discrete Fourier transform of the signal is available in info(spectrum). The spectrum is a sequence of numbers separated by spaces. Each pair of numbers is an amplitude, a, and a phase, φ, representing a component of the transform. The amplitude is in units of ADC counts and the phase is in radians. The pairs are numbered 0 to (N/2)−1, where N is the number of samples in the signal, available in num_messages. The k'th pair of numbers describes the component with frequency k/NT, where T is the sample period. Here we see that NT is the playback interval length and 1/T is the sample frequency. We let f_step = 1/NT, and in our processor code we have the frequency of the k'th component as k f_step. The k'th component is a sinusoid of value a cos(2πkn/N − φ) at time nT. Thus a and φ are the amplitude and phase delay of a cosine wave. We have only N/2 pairs of numbers in our spectrum, but the transform contains (N/2)+1 components. At 512 SPS and a one-second interval, for example, we have 257 components representing frequencies 0, 1, 2, 3,.. 256 Hz. But the first and last components may each be represented by a single real number, and so we use the first pair of numbers in our spectrum to represent the first and last components. The amplitude of the first component, the one for k = 0, is the average value of the signal. The phase of the first component is always zero, so we don't need to record it in the spectrum. In place of the phase of the first component, we record the amplitude of the final, highest-frequency component in the transform. The phase of this highest-frequency component is always 0 or π, so we make the amplitude positive for 0 and negative for π.
The following processor illustrates how to manipulate the individual components of the signal spectrum. We can manipulate individual sample values in the same way. The script calculates the sum of the squares of the amplitudes of all frequency components in the range 2-40 Hz. The script uses the variable band_power to accumulate the sum of squares. The sum of the squares of the amplitudes of all components in the discrete Fourier transform is twice the mean square value of the signal itself. We use the term power because the power dissipated by a voltages applied to a resistor is proportional to the square of the voltage. When we select the components in 2-40 Hz and add up the squares of their amplitudes, we get a sum that is twice the mean square of the signal whose Fourier transform contains only those selected components. We can see what this signal looks like by taking the inverse transform of the 2-40 Hz components alone, and plotting the filtered signal in the value versus time window.
set band_lo 2
set band_hi 40
set band_power 0.0
set f 0
foreach {a p} $info(spectrum) {
if {($f >= $band_lo) && ($f <= $band_hi)} {
set band_power [expr $band_power + ($a * $a)/2.0]
}
set f [expr $f + $info(f_step)]
}
append result "$info(channel_num) [format %.1f $band_power] "
if {$config(enable_vt)} {
set new_spectrum ""
set f 0
foreach {a p} $info(spectrum) {
if {($f >= $band_lo) && ($f <= $band_hi)} {
append new_spectrum "$a $p "
} {
append new_spectrum "0 0 "
}
set f [expr $f + $info(f_step)]
}
set new_values [lwdaq_fft $new_spectrum -inverse 1]
set new_signal ""
set timestamp 0
foreach {v} $new_values {
append new_signal "$timestamp $v "
incr timestamp
}
Neuroplayer_plot_signal [expr $id + 32] $new_signal
}
The band power has units of square counts. When we remove the 0-Hz component from the spectrum, all we have left is components with zero mean. Note the factor of 2.0 division in the above calculation, which converts the square of each sinusoidal amplitude into its mean square value, which we use as a measure of power. By means of this factor of two, the band_power will be the mean square of the filtered signal. The square root of the band power is the root mean square, or standard deviation, or the filtered signal.
We provide the Neuroplayer_band_power command to do all of the work in the above code for us. The routine makes sure that the DC component of the filtered signal is included before plotting, so the filtered signal is always overlaid upon the original signal in the display. You will find Neuroplayer_band_power defined in the Neuroplayer program. The procedure takes four parameters. The first two are the low and high frequencies of the band we want to select. The third is a scaling factor, show, for plotting the filtered signal on the screen. When this factor is zero, the routine does not plot the signal. When the routine plots the filtered signal, it picks a color automatically. The result looks like this (4-s transients filtered to 2-160 Hz) and this (1-s seizure filtered to 2-160 Hz). The fourth parameter is a boolean flag, replace, instructing the routine to replace the info(values) string with the values of the inverse transform. If neither show nor replace are set, the routine refrains from calculating the inverse transform signal, and so is faster.
set tp [Neuroplayer_band_power 0.1 1] set sp [Neuroplayer_band_power 2 20 2 0] set bp [Neuroplayer_band_power 40 160 0 1] append result "$info(channel_num) [format %.1f $tp] [format %.1f $sp] [format %.1f $bp] "
The script above calculates power in three bands: transient (tp), seizure (sp), and burst (bp). The power has units of square counts, and is twice the mean square value of the signal in each band. The result string contains the channel number followed by the three power values with one digit after the decimal point. To convert to μV rms, we take the square root of the band power and multiply by the inverse-gain of the transmitter. Most versions of the A3028 have inverse-gain 0.4 μV/count. Power in the first band can arise from step-like artifacts generated by loose or poorly-insulated electrodes. Power in the second band arises during epileptic seizures. Power in the third band arises during bursts of high-frequency EEG power or during contamination of the EEG by EMG. The script plots the second band with gain two and leaves the third band values in the info(values) string. Subsequent lines of code in the same processor can use the contents of info(values) to operate upon the burst power signal.
The Band Power Processor (BPPv1) uses the band power routine to calculates the power in each of a sequence of contiguous frequency bands specified by a list of frequencies. The frequencies are the upper limits of each frequency band, and the lower limit of the first band we define with a separate constant, which is by default 0.5 Hz.
The Neuroplayer_multi_band_filter routine accepts a list of frequency bands, each specified with a low and high frequency. The routine returns the sum of the squares of the components that lie in at least one of the specified bands. Following the list of frequencies, the routine accepts two further parameters, show and replace, just as for Neuroplayer_band_power. When the routine calculates the inverse transform for show or replace, all components in the discrete Fourier transform that lie within one or more of these bands will be retained, and those that lie in none of the bands will be removed. In the following example, we remove components below 1 Hz, between 48-52 Hz, and above 200 Hz. We show the filtered signal on the screen, and replaces the signal values in the info(values) array so that we can manipulate the filtered signal.
Neuroplayer_multi_band_filter "1 48 52 200" 1 1
The Neuroplayer_filter routine applies a single band-pass filter function to the original signal, but the edges of the band-pass filter are gradual rather than immediate. The band-power and multi-band-filter routines remove components outside a band and leave those inside the band intact. Neuroplayer_filter provides a transition region between full rejection and full acceptance at the lower and upper side of the band. We specify the lower and upper cut-off regions each with two frequencies. The filter routine takes six parameters: four frequencies in ascending order to define the transition regions and the same optional show and replace flags used by the band-power routine. To see exactly what the filter routine does, look at its definition in the Neuroplayer.tcl program.
Here are some further examples of processor scripts.
# Export signal values to text file. Each active channel receives a file
# En.txt, where n is the channel number. All values from the reconstructed
# signal are appended as sixteen-bit integers to separate lines in the file.
# Because this script does not use the processing result string, the Neuroplayer
# will not create or append to a characteristics file.
set fn [file join [file dirname $config(processor_file)] "E$info(channel_num)\.txt"]
set export_string ""
foreach {timestamp value} $info(signal) {
append export_string "$value\n"
}
set f [open $fn a]
puts -nonewline $f $export_string
close $f
# Export signal spectrum, otherwise similar to above value-exporter. The
# script does not use the result string, and so produces no
# characteristics file. Instead of appending the spectrum to its output
# file, each run through this script re-writes the spectrum file.
set fn [file join [file dirname $config(processor_file)] "S$info(channel_num)\.txt"]
set export_string ""
set frequency 0
foreach {amplitude phase} $info(spectrum) {
append export_string "$frequency $amplitude\n"
set frequency [expr $frequency + $info(f_step)]
}
set f [open $fn w]
puts -nonewline $f $export_string
close $f
# Calculate and record the power in each of a sequence of contiguous
# bands, with the first band beginning just above 0 Hz. We specify the
# remaining bands with the frequency of the boundaries between the
# bands. The final frequency is the top end of the final band.
append result "$info(channel_num) "
set f_lo 0
foreach f_hi {1 20 40 160} {
set power [Neuroplayer_band_power [expr $f_lo + 0.01] $f_hi 0]
append result "[format %.2f [expr 0.001 * $power]] "
set f_lo $f_hi
}
# Here's another way to obtain power in various bands. We specify the
# lower and upper frequency of each band.
append result "$info(channel_num) [format %.2f [expr 100.0 - $info(loss)]] "
foreach {lo hi} {1 3.99 4 7.99 8 11.99 12 29.99 30 49.99 50 69.99 70 119.99 120 160} {
set bp [expr 0.001 * [Neuroplayer_band_power $lo $hi 0]]
append result "[format %.2f $bp] "
}
# Add up operating time of all transmitters and print as hours.
set min_reception 20
upvar #0 Neuroarchiver_ol($info(channel_num)) ol
if {![info exists ol]} {set ol 0}
if {$info(loss) < 100-$min_reception} {
set ol [expr $ol + 1.0*$config(play_interval)/3600]
}
append result "$info(channel_num) [format %.1f $ol] "
Processors that assist with event detection, such as classification processors, are longer than our examples. The ECP20 processor, for example, is over two hundred lines long.
[15-AUG-23] Suppose we want to process thousands of hours of data from a dozen transmitters stored on disk. We can open the Neuroplayer and start processing, but we will have to wait hundreds of hours, and our computer screen will be occupied by the Neuroplayer display. We can, however, run the Neuroplayer without graphics from the command line in a console. On MacOS and Linux we can run LWDAQ and the Neuroplayer from within a terminal window. On Windows, we can download a Linux shell like GitBash or Msys and use its terminal window. The Neuroplayer will run as console application or as a background process with no console at all. We can take our list of archives and divide their processing among multiple computer cores. A separate instance of the Neuroplayer running on each computer.
To set up batch processing, start by consulting the Run In Terminal section of the LWDAQ Manual. The idea is to invoke LWDAQ from the command line using the lwdaq script that comes with every LWDAQ distribution. The following command invokes LWDAQ as a background process, executes a configuration script, and passes the name of an archive and a processor into LWDAQ.
lwdaq --no-console config.tcl processor.tcl M1288538199.ndf
The archive is the file ending in NDF. It contains binary data recorded from the subcutaneous transmitters. The processor.tcl file is a text file containing a processor script to create the lines of a characteristics file. The config.tcl file is a configuration script. Here is an example configuration script.
LWDAQ_run_tool Neuroplayer.tcl set Neuroplayer_config(processor_file) [lindex $LWDAQ_Info(argv) 0] set Neuroplayer_config(play_file) [lindex $LWDAQ_Info(argv) 1] set Neuroplayer_info(play_control) Play set Neuroplayer_config(play_interval) 1 set Neuroplayer_config(enable_processing) 1 set Neuroplayer_config(save_processing) 1 set Neuroplayer_config(play_stop_at_end) 1 set Neuroplayer_config(glitch_threshold) 500 set Neuroplayer_config(bp_set) 500 Neuroplayer_baselines_set LWDAQ_watch Neuroplayer_info(play_control) Idle exit Neuroplayer_play
The script sets up the Neuroplayer to read through the archive in 1-s intervals, creating a characteristics file in the manner described above. It sets the glitch threshold and the baseline power values for all channels. When it's done with the archive, it stops and terminates. (The LWDAQ_watch command does the termination.) We assume that that batch job manager will keep track of which analysis processes are still running, and add new ones as the previous ones terminate. We can use the Unix xargs command to schedule the batch processing of all archives in a directory using the following command.
find . -name "*.ndf" -print | xargs -n1 -P4 ~/LWDAQ/lwdaq --pipe config.tcl processor.tcl
The command starts by calling find to get a list of all NDF files in a directory and its subdirectories. We pass this file list to xargs with the pipe symbol "|". The xargs command takes one file name at a time from the list, as controlled by the -n1 option. For each NDF file, xargs invokes LWDAQ with the lwdaq script. In this example, the lwdaq script is in a folder called LWDAQ in our home directory, so we invoke it with absolute path ~/LWDAQ/lwdaq. We pass into LWDAQ a configuration file name and a processor file name. In this case, the configuration file is config.tcl and the processor is processor.tcl. The configuration file sets up LWDAQ to process the archive, which includes setting the playback interval length, glitch threshold, channel select string, and baseline power. The processor file contains the processing instructions themselves, which will be applied to every interval of the archive. An example configuration file is ECP20_Config.tcl, which we can use with processor file ECP20V2R1.tcl. The archive name is the last parameter passed in to LWDAQ, so each instance of LWDAQ started by xargs is equivalent to something like this:
~/LWDAQ/lwdaq --pipe ECP20_Config.tcl ECP20V2R1.tcl M1555422565.ndf
Each archive generates two processes: a shell process defined by the lwdaq and a LWDAQ process defined by the LWDAQ software. The xargs command is watching the shell process, not the LWDAQ process. The -pipe option instructs the LWDAQ process to run without a console but to remain a child of the shell process that created it. When the LWDAQ process terminates, so does the shell process, and xargs moves on to the next archive. The -P4 option instructs xargs to keep four separate processes running simultaneously to process the archives. When one process completes, xargs will start another, until every file in the list has been processed. If our computer provides only two cores, there is no point in using -P4, use -P2 instead.
Once we have applied processing to our data archives to produce characteristics files, we use the characteristics files to look for events, calculate average characteristics, and determine summary information. We call this examination of the characteristics files analysis. When analysis detects events, we call it an event-detector.
The Seizure-Detector, Mark I (SD1) script is an example of an event-detector written in TclTk that we can run in the LWDAQ Toolmaker. The script looks through the characteristics produced by the TPSPBP processor and detects epileptic seizures by examining the development of seizure-band power in the absence of transient-band power.
The Power Band Average (PBAV4) script calculates the average power in a sequence of frequency bands during consecutive intervals in time. You specify the length of these intervals in the script, in units of seconds. So they could be minutes to hours or days. You run the script in the Toolmaker and specify any number of characteristics files with the file browser. Cut and paste from the window to plot in Excel.
The Average Reception (RA) script calculates average reception during consecutive intervals of time. It is similar to the Power Band Average script in the way it reads in characteristics files one after another and prints its results to the screen.
The Reception Failure (RF) script looks for periods of reception failure and writes an event list to the Toolmaker execution window. Cut and past the list into a file to make an event list the Neuroplayer can step through.
The Bad Characteristics Sifter (BCS) script goes through characteristics files and extracts those corresponding to one particular channel, provided that the characteristics meet certain user-defined criteria, such as minimum or maximum power in various frequency bands.
We present the development of event detection using interval analysis in Event Detection. The Neuroplayer's built-in Event Classifier provides analysis that compares intervals with reference cases to detect and identify events in recorded signals.
The Activity Panel is useful when there are many active transmitters, and when we want to see their received and nominal sample rates. The Activity Panel shows us the plot colors of each channel, and allows us to change the colors by clicking on the color boxes. If we want to restore the default colors, we use the Reset Colors button.

We select which channels to display with the Include String. We can list channel numbers, or ranges of channel numbers, or both. We can specify all channels in a particular state. The states are "None", "Off", "Loss", "Okay", and "Extra". The keyword "Active" includes all channels that are active, which are those in states Okay, Loss, or Extra.
Example: The string "1 5 78 Active" includes channels one, five, seventy-eight, and all active channels. The string "1-14 Okay" includes all channels one through fourteen regardless of their state, and all channels that are running correctly.
The states of the channels are displayed in the Activity Panel. When we first open the panel, the default include string is applied to the current channel states, and the list of channels thus generated will be the list the Activity Panel displays until we press Update Panel, or until we close and re-open the panel. When the Neuroplayer has no experience of a channel, its state is "None". When the channel appears in a recording, it will either do so with a sample rate specified in the processor selection string, or the Neuroplayer will guess the sample rate. The user-specified rate in the processor selection takes priority. The sample rate the Neuroplayer is using for each channel is listed in the Activity Panel. Having guessed the sample rate, the Neuroplayer calculates reception, and if reception is less than min_reception of the sample rate, it marks the state as "Loss". If greater than the min_reception, but less than extra_fraction, the state is "Okay", and if higher still, the state is "Extra". If the state of a channel is anything other than "None", and the sample rate drops below the activity threshold, the state changes to "Off". We reset the states with Reset States.
When the Neuroplayer guesses a sample rate, it uses possible values listed in the default_frequency string. If we specify two or more values, the Neuroplayer, on playback, will pick the best match to the data, and this value will show up in the Calibration Panel.
The Calibration Panel allows us to manage the calibration of signal power from one archive to the next. We open the Calibration Panel with the Calibration button.
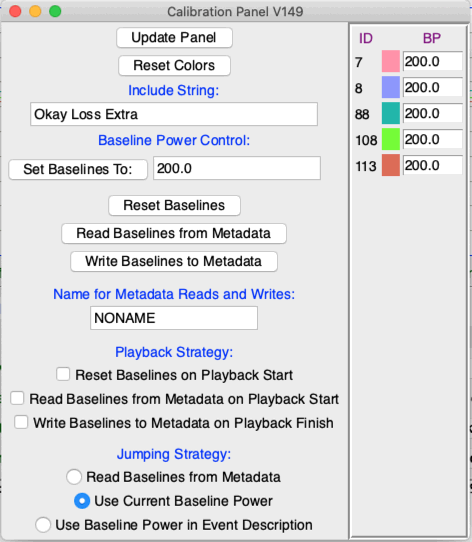
The Calibration Panel shows the baseline power for each channel, and allows us to edit them individually. We select which channels we want to display in the Calibration Panel using the Include String, which works in the same way as the Activity Panel include string. We press Update Panel to put the new include string into effect.
The power of a signal is always useful for event detection. But the sensitivity of our electrodes and the gain of our amplifiers varies from one recording to the next. The result is differences in the amplitude of the recordings, even when the power of the recorded biometric signals is the same. We would rather that these variations were insignificant, and we will of course exert effort to make sure that they are insignificant. But if, despite our efforts, these variations are great enough to undermine our use of the signal power for event detection, we must obtain some measure of the sensitivity of each recording, and use this measure to normalise the recording amplitude. The Neuroplayer's Calibration System allows us to define a baseline power for each recording. The info(bp_n) parameters store the baseline power for channels n = 1..14. If we don't want to use the Calibration System, we don't have to disable it, we simply ignore it. Our interval processor, and whatever analysis we apply afterwards, will not refer to the baseline power values at all.
The baseline powers might represent the absolute baseline power of a signal. When we calibrate a recording, we reset all the baseline powers to a high value, and our interval processor adjusts them downwards to the correct value as it proceeds through the recording. We reset all baseline powers with Reset All. When we use baseline power values in this way, the Calibration System provides various ways to read and write the values to the recording metadata, which we describe below.
The "Playback Strategy" section allows us to instruct the Neuroplayer as to how it is to read and write baseline power calibrations during playback. The "Reset Baselines on Playback Start" option causes the Neuroplayer to reset the baseline power values when it plays back the first interval of an archive. The "Read Baselines from Metadata on Playback Start" option causes the Neuroplayer to read the baselines stored in the metadata under the current read and write name. This read takes place after the reset, if any. The "Write Baselines to Metadata on Playback Finish" option causes the Neuroplayer to save the baseline power calibration developed during playback of the archive to the metadata under the current read and write name. With these options it is possible to go through all archives in a directory tree and determine and store the baseline power calibration for each archive independently in its metadata. Later, we can re-process the data and use the already-developed calibration.
The "Jump Strategy" applies to jumping from one point in one archive to another point in the same archive or another archive. In this case, we might re-process the interval we jump to. When we re-process the events in an Event Library in the Event Classifier, we jump to each event in turn. When we re-process, we may need the baseline power calibration. We can use the calibration stored in the event description, which pre-supposes there is such a calibration stored in the event description. We can use the current baseline calibration for the same channel number. Or we can read a set of baseline powers from the metadata. With these options, it is possible to re-process event libraries from many different, independent archives.
One way to calibrate an EEG recording is to use some measure of the minimum power the signal can achieve. We go through a recording with the same interval length we want to use for event classification, and look at the power of the signal in each interval. We use the minimum interval power as our calibration. If we have our recording divided into one-hour NDF archives, we can perform this calibration on each one-hour period, so we use the minimum power in each hour as our baseline calibration. We set up the Neuroplayer to reset baseline powers whenever it starts playing back a new archive, and to save the baseline powers it has in its calibration array every time it finishes playing an archive. We use a Baseline Calibration Processor, such as BCP2 to calculate interval power and watch for the minimum value. In the case of BCP2, the measure of interval power is simply the standard deviation of the signal, with no filtering applied other than the glitch filter. In BCP3, the interval power is the amplitude of a band-pass filtered version of the signal. We perform the band-pass filtering with a discrete Fourier transform.
Another use of the baseline power values is to hold a scaling factor we want to apply to the signal before calculating a power metric for event classification. We use Set Baselines To to write a single value to all the baseline powers. From here, we can adjust the individual baseline powers by hand so as to account for differences in the baseline amplitude of the recorded signals.
We can save the baseline powers to the archive's metadata string by pressing Write to Metadata, and retrieve previously-saved values by pressing Read from Metadata. When writing a set of baseline powers, the Neuroplayer ignores values that have not been set. We specify a name for the set of baseline powers in the metadata in the "Name for All Metadata Reads and Writes" entry box. If we use three processors, ECP1.tcl, ECP2.tcl, and ECP3.tcl to calculate baseline powers, we can store each set of baseline powers under the names ECP1, ECP2, and ECP3. We can view all baseline power sets in the metadata with the Metadata button in the Neuroplayer.
Processor scripts like ECP1 look for a minima in signal power in a particular frequency band, and use this as the baseline power, but with they also increase the baseline power by a small fraction for every interval so the calibration can adapt to a decrease in sensitivity with time. Such an algorithm is intended to follow a recording from the first hour to the last, with no resetting of baseline power between archives. Before we begin analysis with such a processor, we run it on ten or twenty minutes of data to obtain an initial value for the baseline power, and then start our processing in earnest, going from one archive to the next, carrying the baseline power calibration over from the previous archive. Although appealing, this method of calculating baseline power has two practical problems. If there is an interval in one archive that produces a minimum power that is far too low to be representative of EEG, this minimum stays with the baseline calibration through the subsequent archives. And the requirement that we run the processor for ten or twenty minutes and then go back and start again produces an awkward work flow.
The ECP3 processor contains configuration variables that set it up to calibrate baseline power, calculate metrics, or both at the same time. When ECP3 calibrates baseline power, we assume the Neuroplayer resets the baseline power to some high value when it starts playing an archive, and writes the baseline power to the archive metadata when it finishes the archive. The ECP3 finds the minimum signal power in the archive and uses this as the baseline power. It does not increase the baseline power by increments as it plays the archive. When ECP3 calculates metrics without calculating baseline power, it uses the current baseline power, which we assume has been read from metadata by the Neuroplayer when playback of the archive began. Thus ECP3 is a two-stage processor, operating upon each archive independently. First we run ECP3 on all archives to obtain baseline powers, then we run it on all archives to obtain metrics. The second stage uses the results of the first stage.
When it comes to batch classification, we use existing characteristics files, which were produced by a classification processor, to match intervals with an event library. This comparison does not use the current baseline power values. The baseline power values that applied during each interval described by the characteristics files is always stored along with the metrics. We do not need the baseline power to compare the metrics of a recorded interval with the metrics of an interval in the event library. But we do need the recorded baseline power, if we wanted to translate the metrics back into absolute signal power measurements from which they were obtained.
If we know we need to calibrate the sensitivity of all our recordings, one way to do so automatically is to play through the recordings with a baseline calibration processor. This processor will calculate the baseline power by, for example, looking for the least powerful interval in each hour of recording. We configure the Neuroplayer to reset baseline power at the start of each archive and save baseline power to metadata at the end of each archive. We start playing the first archive and we let the Neuroplayer play on through to the end of the final archive. At the end of each archive, the processor has obtained the calibration of all existing channels and stores their baseline powers in the archive's metadata. The values are stored under the name we specify in the Calibration panel.
Detail: Calculating baseline powers may take ten minutes per hour of recording if we are calculating all the event classification metrics at the same time. We don't need the metrics to calibrate baseline power. To accelerate the calibration, edit the processor and disable metric calculation.
To implement baseline calibration for the Event Classifier, we open the Calibration Panel and disable the resetting of baseline power at playback start, and disable the writing of baseline power at playback end. We enable the reading of baseline power on playback start, and we make sure the name for all metadata reads and writes matches the name under which our baseline calibrations are stored in the recording metadata. For our jumping strategy, we choose to read baselines from metadata.
To disable baseline calibration for the Event Classifier, we open the Calibration Panel and make sure all writing to metadata is disabled. For our jumping strategy, we use the current baseline power.
An Event List is a list of exceptional moments in the recorded data. They could be a list of detected seizure intervals, an a library of various event examples for the Event Classifier. The list takes the form of a text file. Each line of the text file defines a separate event. The Neuroplayer's Event Navigator allows us to navigate through event lists. We pick the event list with the event list Pick button. We move through an event list with the Back, Go, Step, Hop, and Play buttons. Each of these provokes a Jump to a new interval. The Back, Go, and Step add −1, 0, and +1 to the event index, read the event from the event list file, find the archive that contains the event, and displays the event in the Neuroplayer window. The Hop picks an event at random from all the events in the list, and jumps to it. The Play button in the Event Navigator steps repeatedly through the event list until it either reaches the end or we press the Event Navigator's Stop button. The Mark button inserts a jump button in the Neuroplayer text window along with an event record. Click on this button and we return to the interval at which we made the mark. The event record that goes with the mark we can add to an event list to make a permanent record of the interval.
We use the Hop function with large event lists, where our purpose is to determine the false positive rate within the list. Thus we might have a list of ten thousand one-second spike events, and we hop to one hundred of them and find that 98 are true spike events and 2 are not, os our false positive rate is 2% within the list. If the list was taken from one million recorded seconds, the false positive rate is 0.02% within the recording.
Here is an example event list for archive M1300924251
M1300924251.ndf 13.0 3 Transient 3.4 0.995 0.994 0.009 0.136 0.408 0.533 M1300924251.ndf 303.0 3 Hiss 3.4 0.710 0.810 0.644 0.383 0.553 0.699 M1300924251.ndf 402.0 3 Other 3.4 0.513 0.595 0.618 0.473 0.559 0.578 M1300924251.ndf 105.0 4 Rhythm 2.8 0.656 0.226 0.441 0.790 0.324 0.688 1300924642 0.0 4 Quiet 2.8 0.351 0.202 0.723 0.221 0.470 0.216 1300924662 0.0 "3 4 8" "Nothing remarkable here"
Each line contains a separate event. Each event is itself a list of elements. The first element is either the name of an archive or a UNIX timestamp. The second element is a time offset from the start of the archive or from the UNIX timestamp. This offset can be a fraction of a second, but the UNIX timestamp is a whole number of seconds. The third element is a list of channel numbers to which the event applies. The remaining elements are usually a description followed by characteristics, but could contain only a description, or could be omitted. An element containing spaces can be grouped with quotation. In the first few lines above, we have an event type followed by the baseline power at the time of the event, and six metrics used by the Event Classifier.
When the Event Navigator moves between events, it searches its directory tree for the archive named by the event, or for an archive that contains the time specified in the event. If it finds the interval it is looking for, it displays the interval using the current Neuroplayer settings. Otherwise it issues an error message in the Neuroplayer's text window.
The isolate_events parameter in the configuration panel directs the Neuroplayer to set channel_select event channel whenever it displays and event. This isolates the event channel for display. Set this parameter to 0 to see all channels.
The jump_offset parameter in the configuration panel is a time in seconds we add to the event time when we jump to the event. If, for example, we set the jump_offset to −4 and select an 8-s playback interval, we will see the four seconds recorded before and after the event time. By default, jump_offset is zero.
Whenever we jump to a new event, we use the current "Jump Strategy" in the Calibration Panel to determine what will happen to the current power calibration. We can use the baseline power stored with the event description, or we can read baseline powers from the metadata of the archive we are jumping to, or we can use the current baseline power calibration.
The Event Classifier is part of the Neuroplayer. Its job is to take intervals that we have classified by eye, gather them together in an event library, and use this library to classify tens of thousands of intervals automatically. We introduce the Event Classifier in Similarity of Events. We describe the theoretical basis of the Event Classifier in Adequate Representation. At the heart of the classification procedure is the idea that we can represent each interval with several numbers, which we call metrics. Each metric is between zero and one, and represents a particular property of the interval. The power metric, for example, represents the amplitude of the signal. The coastline metric represents how much the signal jumps up and down in the interval. When we describe an interval with n such metrics, we think of the interval as a point in an n-dimensional cube. This n-dimensional cube is the metric space. When there are two metrics, the metric space is a unit square. Its position vertically is given by one metric, and its position horizontally is given by the other. If there are six metrics, we each interval is a point in a six-dimensional unit cube. Our hope is that when two intervals look similar to one another to our own eyes, they will close to one another in metric space. Conversely, when they do not look similar to our own eyes, they will be far apart in metric space. This relationship between similarity in our own eyes and proximity in the metric space will hold true only if the metrics are effective. We have worked hard at devising effective metrics, and we continue to do so.
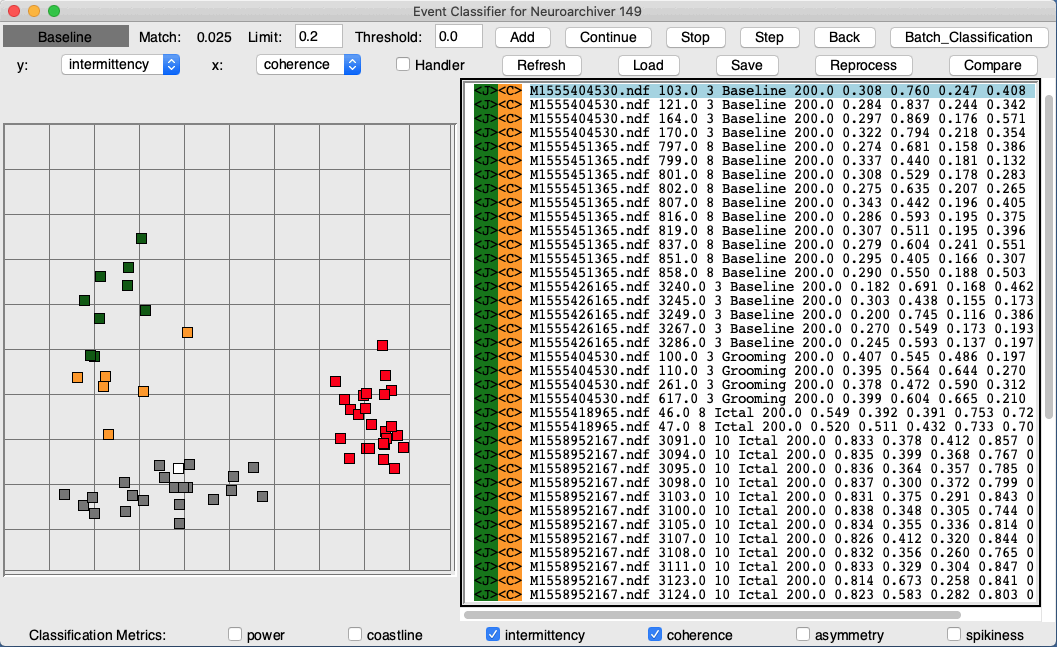
We calculate the metrics with an event classification processor, which is a type of interval processor. Before we can classify our entire recording, we must calculate the metrics for all the intervals it contains, and store them in a text file. This we do with batch processing. The process of building an event library is handled by the Event Classifier panel. Suppose we want to find intervals of EEG that are part of epileptic seizures. We examine the EEG recording in one-second intervals. When we find an interval that we are sure is part of a seizure, we add this interval to our library, and call it an ictal interval. We could call it something else, if we like: "seizure" or "spikes", for example. We also add intervals that are good examples of normal EEG, which we call baseline. Again, we could call them by another name. The names we use are defined in the event classification processor, which is a text file that we can edit with a text editor. The LWDAQ program provides a text editor in the Tools menu. The processor also defines the names of the metrics, and configures the Event Classifier to display and manipulate the event library.
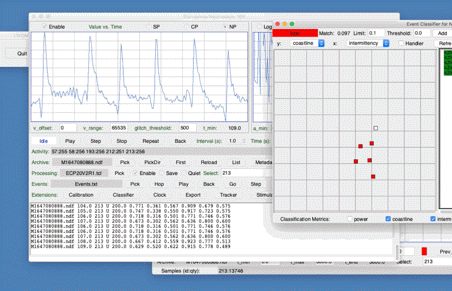
Once we have a library of events, the Event Classifier allows us to save the library as a text file. We can read it in again later, or use it right away. The Batch Classifier is part of the Event Classifier, and its job is to apply our library to the rest of our recording and make lists of events that are similar to ones in our library. For example, we can tell the Batch Classifier to make a list of ictal events, and it will write the list to a text file. Later, we can use event consolidation to combine ictal events into seizures lasting tens or hundreds of seconds, and so count them.
When we press the Classifier button, we open the Event Classifier. The Event Classifier works with an event classification processor an event library to perform automated event detection for long-term, continuous recordings. The event classification processor calculates the metrics used by the Event Classifier. It also gives names to these metrics, defines a list of possible event types, and assigns display colors to the event types.
When we first open the Event Classifier panel, we see two blank squares with some buttons and parameters. The blank square on the left is the event map, and the one on the right is the event library. Before we see something like the colorful display shown above, we have to initialize the Event Classifier with a Classification Processor and load an event library with the Load button. Our latest classification processor is ECP20, which we present in Event Classification with ECP20.
Classifier Demonstration Package: Load a working library, look through real data, and apply the Batch Classifier with our ECP20_Demo (290 MBytes). The package contains twenty-five hours of recordings from mice, all made with the A3028B3 transmitters with bare wire electrodes held in place by screws. The recording includes twenty-two hours from control animals on channels 3 and 8, and three hours from animals injected with pilocarpine, on channels 10 and 12. The included event library shows baseline, ictal, spike, and artifact events. We can display the library events in the Event Classifier map using various combinations of the metrics: power, coastline, intermittency, coherence, asymmetry, and spikiness. The ECP20 metrics are designed to allow us to classify EEG intervals without using a power threshold, so we can set the classifier threshold to 0.0. The package contains the characteristics of all NDF files, but we can delete these and re-create all the characteristics files with ECP20. We can create the characteristics files one at a time using the Neuroplayer, or we can create them several at a time with batch processing. The ECP20_Config.tcl file contains instructions for setting up batch processing of the NDF archives to produce characteristics files. (Thanks to Adrien Zanin and Jean Christophe Poncer, INSERM, Paris, France, for making these recordings available for distribution.)
The Event Classifier operates upon the characteristics of recorded data. These characteristics must conform to a particular format. They begin with a type string. The second characteristic is a real-valued baseline power with at least one digit after the decimal point. The third and subsequent characteristics are real-valued numbers between 0.0 and 1.0, all with at least one digit after the decimal point. These are the interval metrics. The events in the event library have characteristics in exactly the same format.
The first metric we assume to be a measure of the size of the signal, and we call it the power metric. The remaining metrics we assume to be independent of the power of the signal. Any two intervals that look exactly the same in a normalized Voltage vs. Time plot will have all metrics identical except for the power metric.
The event classification processor calculates metric values in two steps. First, it calculates a measure, X, that represents some characteristic of the interval. We might, for example, set X equal to the standard deviation of the signal as a measurement of its power. Second, it passes this measurement through a sigmoidal function to produce a value bounded between zero and one, which we call the metric. The sigmoidal function we use is:
Here Xmid is the value of X for which the metric, Mx, will be 0.5, and y is an exponent that increases the sensitivity of the metric to deviations in X from Xmid. With Xmid = 1.0, for example, and y = 1.0, the metric has value 0.50 for X = 1.0 and 0.33 for X = 0.5. With y = 2.0, the metric still has value 0.5 for X = 1.0, but its value is 0.20 for X = 0.8. In our event classification processors, we apply the sigmoidal function with a line of code like this:
set M_x [Neuroclassifier_sigmoidal $X 0.4 3.0]
Here we have Xmid = 0.4 and y = 3.0 when calculating our metric of X. We adjust the parameters Xmid and y for each metric until the metric spans most of the range 0-1 in the event map. Different interval lengths and epilepsy models may benefit from such adjustments to the sigmoidal calculation.
The Event Classifier allows us to enable and disable each metric individually by checking its enable box at the bottom of the Event Classifier panel. With n metrics enabled, each playback interval and each library event appears as a point in an n-dimensional metric space. If we disable the power metric, the Event Classifier ignores the power metric, and we say the classification is normalized. Classification without the power metric operates only upon the shape of the signal, not upon its size.
All classification processors produce a power metric, and this metric is the first metric printed to the characteristics produced by the processor. The power metric could be obtained from the standard deviation of the signal, the mean absolute deviation, or by summing the squares of the frequency components in a particular frequency band. Our ECP20 processor obtains the power metric by dividing the standard deviation of the signal by its baseline amplitude, and passing the ratio through a sigmoidal function that produces a value of 0.5 when the ratio is 1.0. Although we rarely use the power metric these days, it was an important metric when we first developed the Event Classifier, and the Neuroplayer still retains many tools for dealing with the power metric, including the Calibration Panel. Any interval with power metric lower than the classification threshold will be classified as "Normal", and will not be compared to the events in the library. The classification threshold appears in the Threshold entry box. Set it to 0.0 and no interval will be "Normal". All intervals will be compared to the event library. Set the threshold to 0.5 and only intervals with power metric ≥0.5 will be compared to the event library. All other intervals will be "Normal". The Event Classifier applies this threshold even when it is performing normalized classification. An interval with power metric less than the threshold will be classified as "Normal" regardless of how similar its shape is to an event in the library. The default value of the classification threshold is 0.0, in keeping with our recommendation that we classify signals based upon their shape alone, not their amplitude.
The Event Classifiers's event library is an event list containing intervals we have classified by eye. When the Event Classifier compares an interval to its library, it calculates the separation of the interval from each library event in the n-dimensional metric space. The library event closest to the new interval is the matching event, and the distance between them is the match distance. The Event Classifier displays the match distance next to the "Match" label. If the match distance is greater than than the match limit, the Event Classifier assigns the new interval the type Unknown. Otherwise, the Event Classifier assigns the new interval the same type as the closest library event. We set and view the match limit in the "Limit" entry box.
The event classification processor gives names for each metric. These names appear in the menu buttons above the event map. The processor provides a list of event types and colors for their display in the event map. This list should not include the reserved type "Unknown". The type "Unknown" will always be assigned the color "black". The most important function of the processor is to calculate the interval metrics. Each line in the event library is an event with its classification, baseline calibration, and metrics. When we first start work, we don't have an event library. We must construct our own library, using events from our own recordings. We may be using the baseline calibration or we may not. If not, we can leave the baseline values at their default values.
To begin building an event library, we download an event classification processor, such as ECP20. We pick and enable the processor in the Neuroplayer. We set the playback interval to a time that is short enough so that our shortest events are still prominent, but not so short that these events are often getting lost at the edges of the interval. For spikes, seizures, spike bursts, hiss, and grooming artifact, we like to use one-second intervals, so "1.0" is a good value to start with.
When the Event Classifier encounters interval with the first metric greater than the classifier threshold, it stops. By default, the threshold is 0.0. You could set the threshold to 0.5 so that only intervals with power metric greater than 0.5 will be classified. We recommend that you attempt to perform classification without any use of the power of the signal, but this is not always practical. Sometimes, we must ignore intervals with power less than a threshold if we are to reduce the rate at which we falsely classify normal intervals as unusual intervals. If we want to use the power metric and the power threshold, we must adopt and implement a policy for calibrating the power of our various recordings. As a rule of thumb, we want a power metric of 0.5 to correspond to an unusually powerful interval, so that 10% of intervals have power metric greater than 0.5. We discuss calibration and the Neuroplayer's Calibration Panel in an earlier section. The ECP20 power metric uses the amplitude of an interval divided by the baseline amplitude specified in the Calibration Panel. View your recordings in the Neuroplayer and estimate the average amplitude by eye. For EEG recordings made with the Subcutaneous Transmitter (A3028B), baseline calibration of 200 works well with rats and skull screws, 500 for rats and deeper wire electrodes, and 100 for mice with skull screws (units are sixteen-bit ADC counts). We enable our event classification processor and adjust the baseline powers until we are satisfied that our power metric will be distributed around 0.5 for the intervals we are interested in. It's much easier to use the same baseline power for all channels, so don't give individual channels separate calibrations unless they vary dramatically in their baseline amplitude. Now that we have baseline calibration established, we can start to build our event library.
We go to the start of the first recording file, which is one of your NDF archives. We pick one channel in this archive to start our work. We enter this channel number in the channel select box. We open the Event Classifier panel. We configure the map to display two different metrics, such as power and coastline. We press Continue. The Event Classifier starts playing the recorded signal. It plots each interval as a white square in the event map. If the power metric of the interval is greater than the classification threshold, the Event Classifier compares the interval to its library. If the match distance is greater than the match limit, the interval is "Unknown", and the Classifier stops playback so we can assess whether or not to add this new unknown interval to our library. If the event is uninteresting, we press Continue again. We want to build a library of fine examples of the events we are interested in. We should not include poor examples nor events of no interest to us. If, however, this event is a good example of something we are trying to find in our recordings, or even a good example of something we are trying to avoid, we press Add. The Event Classifier adds the event to our library. We see the event as a new line of text in the event library window. We go to this new event and we press C. The event type changes. Pressing C repeatedly cycles through the event types defined in our classification processor. In the case of ECP16V2, these are Ictal, IctalSpikes, Hiss, Spindle, Artifact, Depression, and Baseline. If none of these types fit the event, we edit the processor script and add another event type to the list of types it defines. We go back a few intervals and press Continue. We come to the same event again, but this time we can assign it our new type with the C button. We can also delete types from the processor script. Every time we assign a new type, we must give it a unique color code.
We proceed through our recording with Continue, adding events to our library when necessary. If we stop at a fine example of an event type, and the Event Classifier already classifies this example correctly, we can refrain from adding the event to our library. We do not want to clutter our library with unnecessary events. We may remove and add events by hand in the text window of the Event Classifier. We press Refresh to sort out the map and the list after such manual edits. After a while, we arrive at a library with several fine examples of each of our event types. We go back to the beginning of our recording and pick a different channel. We repeat the same process, adding the slightly different examples of our event types that we might find in this channel, and in others subsequently. When we are satisfied that our event library is working, we Save to write it to disk.
Do not add events of type "Unknown" to the library. Do not attempt to assign some default type, such as "Other", to events with no specific type. The Event Classifier allows us to extract events of type "Unknown" as well as our specific types. There is no need to give these unknown or uninteresting events a special type. We can always go back through these unknown events and pick some to be library events of a specific type at a later time. The event library should be a list of events of known and definite type. Allow the Event Classifier to resolve ambiguity.
Our library events appear as points on the map and as lines in the text window. The map plots the events in a space defined by two of their characteristics. The Classifier obtains the metric names from the classifier_metrics string, which is initialized by the classification processor. We can change the metrics for the map and re-plot with the Refresh button. To jump to the event corresponding to one of the points, click on the point. We will see the Neuroplayer jump to the event, and the event itself will be highlighted in the Classifier's text window. The map shows how well two metrics can distinguish between events of different types. Each event type has its own color code, as set by classifier_types, which is initialized by the classification processor. We hope to see points of the same color clustering together in the map, and separately from points of different colors. In practice, what we see is overlapping clusters of points, each cluster with its own color.
The Event Classifier lets you enable and disable the available metrics with the check-boxes along the bottom of the Event Classifier window. We look at the various two-dimensional views of our library events. After enough study, we will notice that some metrics do not provide useful grouping of our events, while others do. Some types of seizure, for example, are symmetric, so an asymmetry metric will not help find them. The curse of dimensionality suggests that the number of events we need for classification increases exponentially with the number of metrics. So we should disable metrics we don't need.
The Compare button measures the distance between every pair of library events that have a different type, and makes a list of such pairs whose separation is less than the match limit. The Classifier prints the list of conflicting events in the Neuroplayer text window.
Each event written by the Classifier to the event library window has a J button next to the C button. When we click on the J button, the Neuroplayer jumps to the library event. The archive containing the event must be in the Neuroplayer's directory tree. We can jump to an event in the event map by clicking on its square. When jumping to the event, the Neuroplayer uses our selected jumping strategy to obtain baseline calibration. If we have a fixed calibration for all transmitters in all recordings, this problem of calibration is simple. We use the baseline power in the Calibration Panel. But if each transmitter has its own calibration, and we have multiple transmitters with the same channel number in our body of data, the best strategy with multiple archives is to read the baseline calibration from archive metadata.
We may end up modifying our event classification processor to suit our particular experiment. When we do this, the metrics change. We may eliminate or add metrics. In such cases, we can re-calculate the metrics of our event library with the Reprocess button. During reprocessing, the Neuroplayer steps through all events in the library. All the recording archives must reside in the Neuroplayer's directory tree. As the Neuroplayer jumps to each event in the library, it applies the current processor to the interval it jumps to. Once the event library has been reprocessed, we can look at the library in various map views to see if the new metrics provide better separation of event types.
The Batch Classifier is an extension of the Event Classifier. We can go through an archive with the Event Classifier looking for particular events using the playback and the display in the Classifier window, or we can do so more quickly using Batch Classification. The Batch Classification button opens a new window with its own buttons and check boxes. It applies the event library to previously-recorded characteristics files produced by the same classification processor.

Batch classification uses the classifier threshold, match limit, and metric enable values from the Event Classifier. Each of these appear in the Batch Classifier window. The Batch Classifier will classify as Normal any interval with power metric less than the classification threshold, regardless of any other settings.
If Exclusive is not checked, the Batch Classifier performs classification just as would the Event Classifier. When the power metric is above threshold, and the closest event in the library is closer than the match limit, the interval is classified as the same type as this closest event. In the calculation of proximity, the Batch Classifier uses only the metrics that are enabled. If the closest event is farther than the match limit, the interval is classified as Unknown. If Exclusive is checked, the Batch Classifier ignores all events in the library that are not of a type selected by check boxes in the Batch Classifier window. The Batch Classifier finds all intervals that lie within the match limit of the selected types and classifies them as one of those types.
Detail: Suppose one of our types is Baseline and we want to find intervals that are within 0.1 of our library baseline events, regardless of power metric, and not using power metric in the comparison. We disable the power metric and check Exclude. We set the threshold to 0.0 and the limit to 0.1. We will get a list of events that are, according to the metrics, of similar shape. We look at them in a normalized VT plot to find out if they are indeed of similar shape. This is a test of our metrics, one among many that we must perform before we can be confident in our event detection.
Before we start batch classification, we must select input files and specify the output. The input files are characteristics files. We can select them in of two ways. We can select individual files in the same directory using the Pick Files button. We can select all files in a directory tree that match a pattern with the Apply Pattern to Directory. The pattern uses "*" as a wildcard string and "?" as a wildcard character.
The output file is an event list. But default, the Batch Classifier produces a list of events in one file. Each line describes a single event. We can select it in the Neuroplayer and navigate through them as we like. We specify the file with the Specify File button.
If we have characteristics files with names in the form Mx_s.txt, where x is a ten-digit timestamp and s is a string naming a classification processor, or any other name, then we the Batch Classifier can generate separate event lists for each characteristic file. When we specify the output file name, we enter a name for the event list for the first characteristics file, in the same form as above, perhaps M1234567890_Events.txt. Every time the Batch Classifier moves to a new characteristics file, it will open a new event list, replacing the timestamp in the previous event list name with the timestamp taken from the new characteristics file name.
In addition to the list of events, the Batch Classifier produces one summary line for each file. This line contains the file name, excluding directory path, and a string of integers. In purple are the selected channel numbers, and each of these is followed by the count of each selected type of event. We can cut and paste these counts into a spreadsheet, and sometimes this is all the data we need from the Batch Classifier. There is a checkbox for each channel number, so we can select which channels we want to search for events. There is a checkbox for each event type, so we can select which events we want to find.
If Loss is checked, the Batch Classifier will add two numbers to the text window output for each enabled channel. The first number is the number of loss intervals found in the characteristics file, and the second is the total number of intervals found. We note that total signal loss due to failure of a transmitter, or omission of a transmitter from the recording system, has two possible manifestations in the characteristics file, depending upon how the processing was set up. If the channel was specified explicitly in the Neuroplayer's channel select string during processing, there will be an interval recorded in the characteristics file regardless of whether or not any samples are present. But if the channel select string was just a wildcard (*), there will be an interval only if there is some minimal number of samples is present.
The Unknown event type is an event that differs by more than match_limit from all existing events in the library. If we are searching for one particular type of event in our data, such as a Spike, we could fill our event library with spike events, and assume that anything with a match distance of 0.2 or less must be a spike, and anything else is not a spike. We set the match_limit to 0.2 in the Batch Classifier Window or the Classifier window (the two windows refer to the same parameter). The Batch Classifier will classify each event as either Unknown or Spike.
The Batch Classifier makes no use of the baseline power values recorded in the characteristics files it takes as input. The comparison between each interval in the characteristics files and each event in the library is done on the basis of the metrics alone. We need the baseline power to calculate the metrics in the first place, but we do not need the baseline power to compare the metrics.
The Event Handler is a program executed by the Event Classifier. When the Classifier and the Neuroplayer are operating together, the Classifier plots the current interval for each selected channel as a point in its map, and classifies each interval with its library. An event handler is a program the Classifier executes after classifying each selected channel. The event handler takes the form of a Tcl script stored in the Classifier's handler_script parameter. a Tcl script that takes action based upon the nature of the events it encounters during play-back. We enable the event handler with the Handler box checked. By default, the handler script is empty and does nothing. But if the string contains a Tcl script, the Classifier will attempt to execute it.
Example: We wish to flash a lamp whenever we encounter a Seizure event while playing live data recorded from an animal. We set the handler_script to a program that checks the current event type. If the event type is Ictal, the handler sends commands to 910 MHz Command Transmitter (A3029C), which in turn transmits a stimulus command to an Implantable Sensor with Lamp (A3030E).
The Event Handler has access to a selection of Event Classifier local variables, such as type, which contains the type of the current event. The following table lists the variables the event handler can use, and their values.
| Name | Value |
|---|---|
| id | the channel number in which the event occurred |
| event | the event itself |
| closest | the closest event to this one in the event library |
| type | the name of the event type |
| fn | the archive file in which the event occurs |
| pt | the play time within the archive at which the event occurs |
| info | the Neuroplayer_info array |
| config | the Neuroplayer_config array |
The info and config variables are the Neuroplayer information and configuration arrays. Thus we would obtain the value of the playback interval with $config(play_interval) and the current recording time with $config(record_end_time). The event variable contains a string describing the current event in the same way it would appear in an event list. The closest variable contains the closest event in the library.
The following example responds to events of type Ictal by writing a message in red to the Neuroplayer text window, giving the play time and channel number.
if {$type == "Ictal"} {
Neuroplayer_print "Ictal event on channel $id at time $pt." red
}
One way to define the handler script is with a Classification Processor. A Classification Processor already defines the types and colors of events, and the names of the Classifier metrics. It can also define the value of event_handler. The following lines would establish the above handler script for the Classifier. We declare the entire script as a string with curly braces marking its beginning and end.
set info(handler_script) {
if {$type == "Ictal"} {
Neuroplayer_print "Ictal event on channel $id at time $pt." red
}
}
The Stimulator Tool, which you will find in the LWDAQ Tools menu, allows us to control and monitor Implantable Stimulator-Transponders (IST, A3041). We open the Stimulator with the Stimulator button in the Neuroplayer. We set it up to control our ISTs, and then we can call upon it to initiate stimuli from our event handler using the Stimulator_transmit procedure. Whenever the Stimulator transmits a Start command, it prints the sequence of bytes that make up the command to its text window. We cut and paste these bytes into an event handler script. Here is the print-out for a stimulus of 100 regular pulses, each pulse 10 ms long, with current seeting 8, at frequency 10 Hz in the IST with ID 0x6EEA, and including an acknowledgement from the IST using SCT channel number 1.
Stimulator_transmit "110 234 1 8 1 71 0 12 205 0 100 0 6 1 3 17"
To make this script into an Ictal event responder for all channels, we replace the fourteen in the line above with "$id" to insert the current channel number. Now we can define the event handler in our classification processor like this:
set info(handler_script) {
if {$type == "Ictal"} {
Stimulator_transmit "110 234 1 8 1 71 0 12 205 0 100 0 6 1 3 17"
}
}
Each time the classifier encounters an Ictal event, it flashes the lamp for 10 s. Note that the Stimulator Tool must be open for the above commands to work. Here is a more complicated event handler that opens its own text window and reports its activity. We present the script exactly as it would appear defined in a classification processor.
set info(handler_script) {
upvar #0 event_handler_info h
set w $info(classifier_window)\.handler
if {![winfo exists $w]} {
# Here are the global variables the event handler uses.
catch {unset h}
set h(ip) 10.0.0.37
set h(socket) 1
set h(on) 0104
set h(off) 0004
set h(t) $w\.text
set h(id) 21
# Create graphical user interface for handler.
toplevel $w
wm title $w "Event Handler Control Panel"
LWDAQ_text_widget $w 70 10 1 1
# Print some information.
LWDAQ_print $h(t) "Close this window to reset the handler." purple
LWDAQ_print $h(t) "Edit processor script to change parameters." purple
LWDAQ_print $h(t) "Driver ip Address = $h(ip)"
LWDAQ_print $h(t) "Octal Data Receiver Socket = $h(socket)"
LWDAQ_print $h(t) "Watching channel number = $h(id)"
}
if {$id == $h(id)} {
set sock [LWDAQ_socket_open $h(ip)]
LWDAQ_set_driver_mux $sock $h(socket)
if {($type == "Ictal") || ($type == "Spike")} {
LWDAQ_print $h(t) "Activate: Channel $id at $pt s in $info(play_file_tail)."
LWDAQ_transmit_command_hex $sock $h(on)
} {
LWDAQ_transmit_command_hex $sock $h(off)
}
LWDAQ_socket_close $sock
}
}
This handler pays attention only to one channel, as defined in its own h(id) parameter. When first executed, the handler creates a window. The script uses the X1 output of an Octal Data Receiver (A3027) to turn on a lamp or some other stimulus with a logic HI when it encounters an Ictal or Spike event on any channel. When it encounters any other kind of event, it turns the stimulus off.
The Neuroplayer provides simultaneous playback of synchronous video recordings made with one of our Animal Cage Camera and the Videoarchiver Tool. You can use all the usual Neuroplayer navigation buttons with the video playback, including those used to navigate through event lists. The video and signals will be displayed synchronously to within ±50 ms. Use the video PickDir button to select the top of the directory tree containing the video files. These files will have names Vx.mp4, where x is a ten-digit Unix Time, just as we use in the names of NDF files. Enable the video playback by checking the video Enable button. Set the playback interval to 1 s or greater. When video playback is enabled, the signal playback pauses until the video completes. While the video is playing, the background of the Neuroplayer state label turns blue. If you have set the Neuroplayer to Play, the Neuroplayer will move on to the next interval as soon as the video of the current interval has completed. It will display the signal of the next interval, and then start playing the video of the next interval.

To try out the video playback, download and decompress our Test_05JUN18 archive, which contains one ten-minute NDF file recorded from an Animal Location Tracker (A3032C) and ten one-minute videos recorded with our Animal Cage Camera (A3034X). There are four transmitters in a Faraday Enclosure (FE2F) on top of the ALT platform, along with a clock. As we open and close the door, and as we handle the transmitters, we see large steps and wave bursts on their signals. Unzip and select its NDF file as the playback archive, and the directory itself as the Video directory.
Video playback will not provide accurate synchronization when you select a playback interval less than one second. If you attempt to play video and signal with an interval shorter than one second, the Neuroplayer will generate an error. By default, the video will play at ×1.0 speed, but you can slow it down or speed it up by entering a number from 0.1 to 3.0 for video_speed in the configuration panel. When dimensions of the video are controlled by video_scale and video_zoom. The scale takes the original video and multiplies its width and height to create a new image that is either larger or smaller, with a corresponding increase in the number of pixels in the image. On Windows and Linux, we set scale to 0.5 so that the size of the raw image is four times smaller than the original image. This is the only way we can ensure that playback of the video can proceed at full speed. The zoom takes the image and contracts or magnifies the image as it is drawn on the screen. On Windows, Linux, and Raspbian we set zoom to 2.0 so as to restore the original size of the image. In theory, we should be able to see a degredation in resolution going from drawing the original image to drawing a shrunk and then expanded version of the original image, but in practice the compression used to create the original image smooths out edges in such a way that it is hard for us to tell the difference between these two presentations of the same file. On MacOS, however, we set zoom and scale to 1.0 and view the original image directly, because our image display runs far more quickly on MacOS.
Recording from an Animal Location Tracker (A3038, ALT) contain not only telemetry signals but also the microwave power received by the tracker's detector coil array. The A3038 provides fifteen detector coils in a plane, plus one auxiliary detector that we can connect to an external antenna. Each SCT sample recorded by an A3038 consists of twenty bytes: four bytes for the telemetry message and plus sixteen bytes for the power measurements. We refer to these sixteen bytes as the payload of the SCT message. The metadata of an ALT recording specifies the length of the payload and also gives the coordinates of the tracker coils centimeters.
The Telemetry Control Box (A3042, TCB) does not provide power measurements from all of its antennas, but it does identify the "top antenna" and the "top power" for each sample. The top antenna is the antenna that received the greatest signal power. The top power is the power received by the top antenna. The Neurotracker treats TCB recordings as if they were ALT recordings in which all antennas receive no power, with the exception of the top antenna, which receives the top power.
The Neurotracker calculates the power centroid for the coil array using a weighted sum of its coil powers. In the case of an ALT, this can be anywhere between the coils. In the case of a TCB, this centroid will always lie exactly on the coordinates of the top antenna. We specify the locations of the coils or antennas with a list of three-dimensional coordinates. We choose the origin of our coordinate system so that no coordinates are negative, and the z coordinate is always greater than zero. These constraints allow us to reserve zero and negative coordinates to indicate loss of signal later on in our analysis of tracker data. The units we choose for our coordinates are arbitrary. For ALTs, however, our default coordinates are in centimeters. An ALT platform has all its coils arranged in a plane, all at the same z-coordinate. But ALTs can be reconfigured to operate with coaxial antennas in arbitrary locations, and TCBs are expected to have their antennas distributed in three dimensions through Faraday canopies and enclosures. Thus the Neutotracker insists upon three-dimensional coordinates for all antennas. The Neurotracker Panel itself, however, shows only a projection of the power centroid and coil positions in the x-y plane. In the metadata of an NDF file, we specify three-dimensional locations with "alt" field. We can either use the default coordinates for our ALT or TCB, or we can use the Neurorecorder's customization string to write our own coordinates to the NDF file's metadata. Thereafter, these coordinates are read and applied automatically by the Neuroplayer.
The Neurotracker calculation of location for a TCB is simple: pick the top antenna position. For an ALT, with its array of power measurements, we use a power centroid. The power centroid is not a reliable measurement of the absolute position of the animal, because the distribution of power is strongly affected by the orientation of the transmitter, even if the transmitter remains in the same location. But the centroid is a reliable measurement of the magnitude and direction of the animal's movement. The Neurotracker uses the magnitude of the power centroid velocity to obtain activity in centimeters per second. When combined with video blob-tracking, the power centroid velocity provides us with 100.0% reliable identification of animals cohabiting in a cage, provided each animal is implanted with its own telemetry device.
The power centroid calculation is controlled by four parameters: a decade scale, an extent radius, a sample rate, and a filter divisor. The Neurotracker rejects any coils that are farther than the centroid_extent from the measured location of a transmitter. The detector coil power measurements are unsigned eight-bit numbers proportional to the logarithm of the microwave power received by each coil. The decade_scale is the change in power measurement that corresponds to a factor of ten increase in the weight we give to each detector coil in our centroid calculation. The sample_rate is the number of centroid measurements we want to make per second. In theory, the Tracker can make one location measurement per sample it receives from a transmitter. But we obtain better rejection of interference if we allow the Tracker to use the median of a few dozen power measurements. When measuring the position of an SCT transmitting 128 SPS, we recommend a Neurotracker sample rate no more than 16 SPS. The filter_divisor configures a low-pass filter we apply to the power centroid before exporting, plotting, or determining activity. The corner frequency of the low-pass filter is equal to the sample rate divided by the filter divisor. With 16 SPS and divisor 128, we have a 0.125-Hz corner frequency, which gives the power centroid coordinates and the activity measurement a time constant of 1.3 s. When we are interested in the distance moved by an animal rather than whether or not it is awake or asleep, we can use the low-pass filter to attenuate rapid, alternating movements, thus making the activity less sensitive to head shakes and scratching. To disable the low-pass filter, set the filter_divisor to one (1).
The Neurotracker displays the path of each transmitter as directed by the persistence parameter. When None, only the present measurement is shown. When Path, the positions are drawn as a line from point to point. When Mark, each position receives a small mark. When Coils is checked, circles appear on each detector coil center. Black filling indicates the lowest power observed at any coil. White filling indicates the greatest power observed. The intensity in between is graduated according to the logarithmic power measurements provided by the tracker.
The Tracker will not attempt to make new measurements if telemetry reception is poor. If reception in the playback interval is less than the tracker_min_reception, the Tracker will use the most recent valid location measurement as the new location measurement. If reception stops suddenly, the transmitter will appear to remain in the same exact place. The Exporter allows us to write activity, filtered power centroid, and power measurements to disk.
[19-APR-23] To export data from NDF files into other formats, we can use interval processing with a processor script that writes the NDF data to a text file, an EDF file, or any other file format. We describe the available export processors in the Exporting Data section of our Event Detection page. The easiest way to export data, however, is with the Neuroplayer's built-in Exporter, which we open with the Export button. The Exporter will export signals and tracker data to one of several output formats. The Exporter will translate thousands of hours of recordings as they are recorded to disk by a Neurorecorder, or it will extract a short segment of a recording. The exporter will also combine short video files into longer video files that begin and end at the same time as the exported signal files. Thus we can use the Exporter to extract events of interest with an accompanying synchronous video. We begin exporting with the Start button. We abort with Abort. We pause the export with the Stop button in the Neuroplayer, and resume with the Play button in the Neuroplayer.

To try out the Exporter, we invite you to download an example recording. Our EDF_Demo.zip recording provides video of a Subcutaneous Transmitter (SCT) being moved around in a Faraday enclosure. The telemetry signals include three voltages and a temperature. Our Test_21AUG20.zip recording provides a single, continuous video file with recordings from SCTs mounted on mouse toys moving around on an Animal Location Tracker (ALT). In both cases, the video is taken with one of our Animal Cage Cameras (ACC).
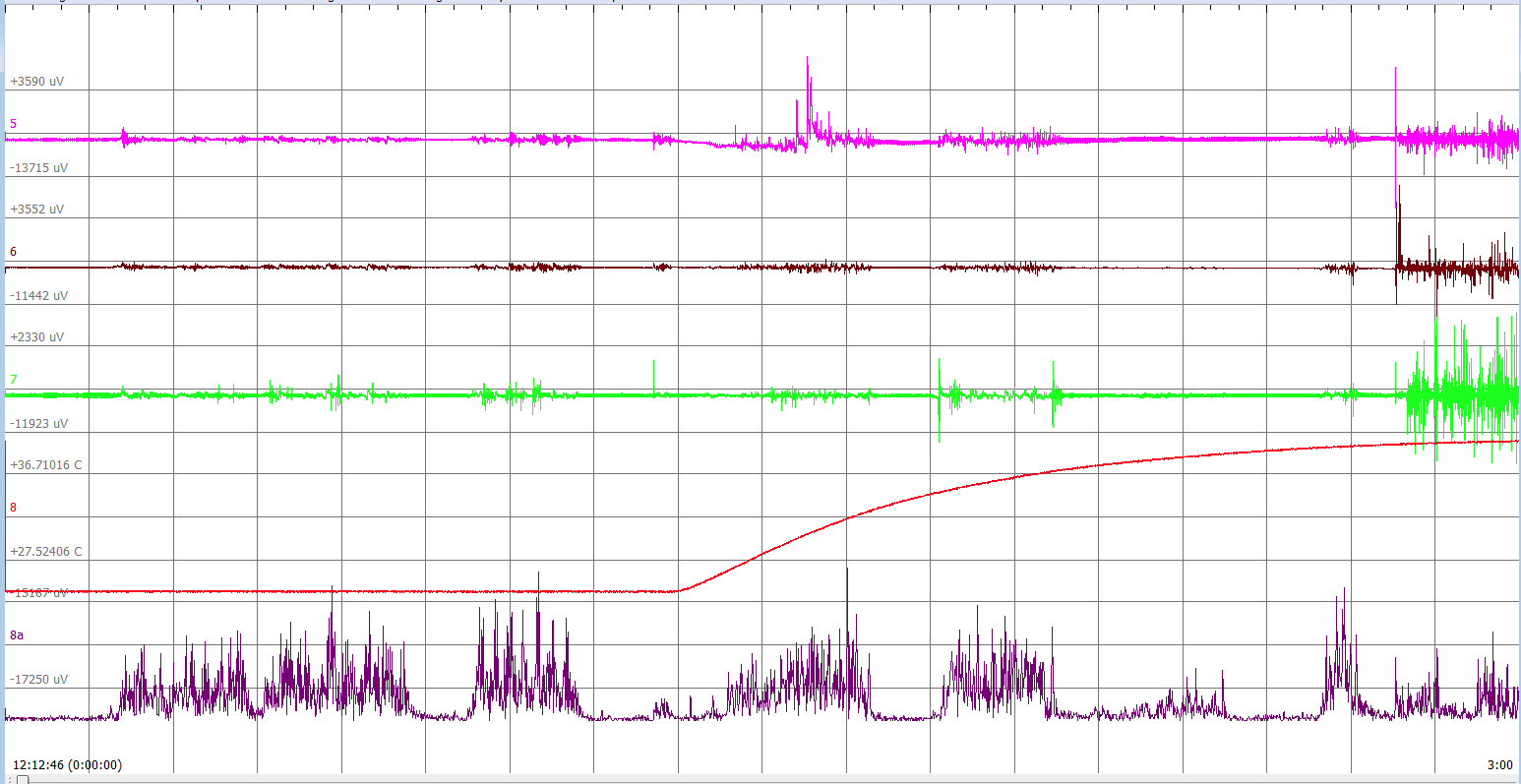
The Exporter will translate a segment of an NDF recording into another format, or multiple segments, or entire archives, or multiple archives. The Exporter supports the export of time-varying voltages from Subcutaneous Transmitters (SCT), location and power measurements from Animal Location Trackers (ALT), and video from Animal Cage Cameras (ACC). We can export to separate files or to a single file. We have a choice of export file formats for signals, location, and power measurements. In the paragraphs below, we go through the steps required to define an export: specifying the start time, duration, repetitions, channel numbers and sample rates, the data to be exported, and the format of the output file. Note that the Exporter does not export to NDF file format. If we want to excerpt a section of an NDF file and write it to disk as another NDF file, we use the Excerpt button in the Overview.
The start time of our export is displayed next to the Start: label. If we wish to export starting at time 10 s in a particular archive, we use the Neuroplayer to select the archive and jump to time 10 s. We press Interval Beginning and the start time changes to the date and time that corresponds to the beginning of our chosen interval. If we wish to export from time 0.0 s, we select our archive and use Archive Beginning. If we wish to specify an absolute time, such as 06:00:00 on 17-MAY-19, we use Clock to open the Clock Panel and navigate to the absolute time we want, then use the Interval Beginning button. The navigation will succeed only if an NDF covering our absolute time exists in the Neuroplayer's directory tree.
Each export segment covers a certain length of time in the original recording. We use the Duration entry to specify this length of time in seconds. The Duration entry accepts mathematical expressions, so we could specify a day-long duration with "24*60*60" or with "86400". The duration can cover part of an NDF archive or multiple archives. For the duration to be implemented correctly, however, it must be exactly divisible by the playback interval. At the end of the export segment, the Neuroplayer will step to the interval following the end of the export. If we press Interval Start, the next export segment will begin where the previous segment ended. There will be no duplication of export, nor will there be any omission of signals or video.
Within a single export file, we must have a fixed set of signals, and each signal must have a fixed sample rate. At the start of any export, we must specify which channels we want to export along with their sample rates. We use the channel selector string, which is available in the Select entry. A wildcard "*" for this string is not accepted by the Exporter. We must enter at least one channel number with its sample rate in the format "ID:SPS". The sample rate must be power of two between 16 and 4096, for such are the sample rates used by our telemetry devices. To specify channel 24 with sample rate 512 samples per second (SPS), enter "24:512". To specify multiple channels, list them separately with spaces in between, as in "24:512 57:128 12:1024 19:128". If we have navigated to a point in our recording where we have robust reception of all signals we wish to export, we can use the Autofill button to generate the channel selector string. If some of the channels we want to export do not appear in the first interval, but start later in our recording, autofill will not find them, so we must enter them by hand.
We enable the export of telemetry signals with the Signals flag. If we set the Centroid flag, we enable the calculation and export animal location tracker power centroid positions. With Powers set, we enable the export of tracker coil powers. Set both flags and we export both centroid and powers to the same file. The locations and powers will all be zeros unless the NDF file was recorded from an ALT. We control how the centroid should be calculated, and we specify the sample rate for both centroid and power measurements, using the Neurotracker Panel, which we open with the Tracker button. If we set the Video flag, the Exporter will create a simultaneous video to go with the exported signals. During the export process, the Exporter will search the Neuroplayer's video directory tree to see if it can find all the files it needs to produce a complete video for the export segment. If it cannot find a complete video record, it prints a warning. The video will start at the same moment as the export files and it will have the same duration. The exported video will be written to the export directory, and it will be named Vx.mp4, where "x" is the Unix time of the start of the export segment.
Export files are written to the export directory. We choose the export directory with the PickDir button. When Combine is not set, the signal carried by each telemetry channel will be written to "Ex_n.y", the physical activity of the telemetry device will be written to "Ax_n.y", and the raw location tracker measurements of the telemetry device will be written to "Tx_n.y". Here, "x" is a ten-digit Unix timestamp, "n" is the channel number, and "y" is the file format. We use prefix "E" for backward compatibility with earlier versions of the Exporter, in which "E" referred to "export". We use "T" for "tracker", and "A" from "activity". When Combine is set, the telemetry signals for all selected channels are combined into one file "Ex.y", the activity of all devices is combined into "Ax.y", and tracker measurements of all devices are combined into "Tx.y". The Combined flag has no effect upon video export, which always generates one file per export segment. The Exporter can work on only one set of videos at a time. In order to create simultaneous, stereoscopic views of an experiment, we must run the Exporter twice: once for each camera.
We select the output file format with the TXT, BIN, and EDF buttons. We introduce these formats now, but we describe them in more detail below. The "TXT" format consists of integers expressed as ASCII characters separated by spaces or line breaks. The TXT format allows us to specify a text-only header that will be placed at the top of all TXT export files. The "BIN" format consists of binary integers in big-endian byte order: the most significant byte is written first. The "EDF" format is a text header with binary data, as defined by the EDF specification. The EDF format is designed to store scalar, time-varying signals. We can store telemetry signals and device activity in EDF files, but the format does a poor job handling the multi-dimensional centroid and power coil measurements provided by animal location trackers. The EDF option is incompatible with the Centroid and Powers options.
The Exporter reads NDF files using the Neuroplayer. The Exporter is more efficient when operating upon a longer playback interval. But a longer playback interval further restricts our choice of segment duration, because the duration must be an exact multiple of the interval. We find there is little advantage in using an interval longer than eight seconds, so we recommend eight-second intervals for export, and durations that are a multiple of eight seconds. If we are exporting to separate files, we can change the playback interval during the export without causing any disruption of the export. But if we are combining measurements from more than one channel into a single file, we must leave the playback interval unchanged throughout each export segment, or else the measurements stored in the file will become confused. We can accelerate export by turning off the value and amplitude plots in the Neuroplayer. With the plots turned off and eight-second intervals, the Exporter takes two minutes to write one hour of 512 SPS telemetry to a text file when running on a 1-GHz machine.
The Repetitions entry allows us to specify the number of times we want the Exporter to perform the export segment we have defined, each segment starting where the previous segment ended. The Exporter decrements the repetitions value at the end of each export, and if it remains greater than one, the Exporter starts again, just as if we ourselves had pressed Interval Start followed by Start Export. If repetitions is "*", the Exporter continues exporting until it reaches the end of the available NDF recording. When there is no more data to export, the Exporter waits for more data to be written to the archive or for a new archive to be written into the directory tree. As the data is written, the Exporter continues the export. If we want our exports to be done in real time, we can leave the Exporter running while we are recording, and it will export that data as it arrives.
Text Format (TXT): All numbers are written to files as integers expressed with ASCII characters and separated by spaces or line breaks. If we have the telemetry signal for one channel in Ex_n.txt, we will see one value between 0 and 65535 on each line of the file. If we have the activity signal in Ax_n.txt, each line is an activity measurement in centimeters per second. If we have centroids and powers in file Tx_n.txt, each line will consist of the filtered centroid position x, y, z in centimeters followed by one power value for each detector coil. For activity, centroid, and powers, the export files will contain sample_rate lines per second, as defined in the Tracker Panel. If we combine output from different channels into the same file, the format of the text file will depend upon the playback interval. In each playback interval, the Exporter works the channels in the order they are listed in the channel selector string. If the selector is "10:256 12:512" and the playback interval is one second, the Exporter writes 256 values to Ex.txt for No10 followed by 512 values for No12. It repeats the same process in the next eight-second interval. If the tracker sample_rate is 16 SPS, the Exporter writes 16 lines for No10 followed by 16 lines for No12. The TXT format provides an optional header that the Exporter will write to the start of all TXT files. We can specify a TXT header with the TXT Setup Panel. Presse the Save button in the panel to save the header. Before saving, the Exporter removes all leading and trailing white space from the header.

Binary Format (BIN): The BIN format is one quarter the size of the TXT format and half the size of the original NDF format. All telemetry signal values are written as unsigned two-byte integers in big-endian byte order. The most significant byte is written first. We store the filtered centroid position as x, y, and z in whole millimeters (not centimeters). Each coordinate is stored as an unsigned, two-byte, big-endian integer. We store the activity in whole millimeters per second (not centimeters per second). The coil powers are each a single byte 0-255. When data from each channel is written to a separate file, the playback interval has no effect upon the format of the file. The telemetry signal file, for example, is an uninterrupted sequence of samples, each a two-byte integer. The tracker file is an uninterrupted sequence of binary records, each consisting of six bytes for the filtered centroid position and one byte for each detector coil. If we combine data from multiple channels into one file, the format of each file will depend upon the playback interval. If the channel selector is "10:256 12:512" and the playback interval is eight seconds, the Exporter writes 2048 two-byte integers to Ex.bin for No10 followed by 4096 two-byte integers for No12. In the next eight-second interval, it does the same thing. If the tracker sample_rate is 16 SPS, the Exporter writes 128 activity values to Ax.bin for No10, 128 values for No12, and then repeats in the next eight-second interval. It writes 128 centroid and power measurements to Tx.bin for No10 followed by another 128 for No12. Each tracker measurement contains the same number of bytes: six bytes for position and one byte for each coil power.
European Data Format (EDF): The EDF file begins with a text header that specifies the signal names, sample rates, and additional metadata, such as the transducer type and a description of the pre-filtering applied by the transducer. We can specify all these names and values with the EDF Setup Panel, which we open with the EDF button in the Setup section of the Exporter. We use the EDF Setup Panel to configure the export of signals to EDF files.

We used the above headings to create E1642694241.edf, which you can download, unzip, and open with an EDF viewer. Read the file with the Setup Panel's Read button and the headings will appear in the EDF Setup Panel. The Read button allows us to read the header of an EDF file we created previously, so that we don't have to type the same values in a second time. After reading the header of an EDF, the Setup Panel re-draws itself. We can force a re-draw at any time with the Refresh button. In this example, we have transmitters with different amplifier gains, but we are applying a sweep of the same amplitude to all four channels. The EDF viewer will display the four signals with the same amplitude because the Min and Max fields in the header allow us to specify the dynamic range of each amplifier correctly.

The Exporter provides export to EDF for telemetry signals and device activity, but not for tracker centroid or tracker power measurements. In the EDF header, a telemetry signal will be named after its channel number. An activity signal will be named after its channel number with a suffix "a". The sample rate of all activity measurements is equal to the sample_rate in the Tracker Panel. The filtering we apply to the activity is defined in the same panel. In the EDF Setup Panel we can edit the transducer field for each activity signal, but we cannot edit any of the other fields, because these are fixed by the activity calculation.
To import data from some other recording system, we must translate into NDF so the Neuroplayer can read it. We have several import scripts available, all of which we can run inside LWDAQ with the Run Tool command or in the LWDAQ Toolmaker. We present these importers in the Importing Data of our Event Detection page.
The Neuroplayer allows us to inspect the content of recorded data in detail, message by message if necessary. At times the Neuroplayer might report errors in its text window, something like this:
WARNING: Clock jumps from 43904 to 44060 in M1295029550.ndf at 584 s.
These messages will be in blue. They mean that something has gone wrong in the acquisition of data by the Receiver Instrument. In the example above, the Neuroplayer detected a jump in the value of the clock message from 43904 to 44060. The next clock message should always be one greater than the last, with the exception of clock message zero, which of course follows clock message 65535. The clock messages are inserted in the message stream by the data receiver (such as the A3018) regardless of the incoming transmitter data. They are the messages with channel number zero.
The data receiver inserts 128 messages per second, so they are spaced by 7.1825 ms. In the above example, the clock has jumped by 136 instead of 1. We are missing just over 1 s of data. There are several possible explanations for the missing data. The data receiver buffer might be overflowing because data acquisition is not keeping up with data recording. Or we may have two Neurorecorders downloading from the same data recorder. Or the data receiver may be resetting itself because of power supply failure or electrostatic discharge.
The Neuroplayer lets us look more closely at the incoming messages, which is useful when diagnosing problems. Try clicking the verbose check box. Now we will see more detailed reports of reconstruction in the text window. Press Configure and set show_messages to 1. Press Step in the Neuroplayer. We will see detail of the number of errors in our playback interval, and a list of the actual message contents, as provided by the print instruction of the Receiver Instrument's message analysis. If there is an error in the playback interval, the list of messages will center itself upon that error. Otherwise the list will begin at the start of the interval. We set the number of messages the Neuroplayer will print out for us with the show_num parameter.
Instead of translating NDF archives into another format, we may wish to read the archive directly from NDF into some other program of our choosing, such as Matlab, Python, or LabView. In order to read the recorded signals correctly from the NDF file, we must must understand the NDF file structure in detail. The signal recorded in the NDF will be imperfect: some messages will be missing due to reception failure, the messages are not uniformly spaced because of transmission scatter, and there will be some number of bad messages to eliminate. After we read the data from the NDF file, we must reconstruct the signal. The format of the NDF header is described here. When we open an NDF file with a Hex editor we see the header block, a load of zeros, and then the transmitter data itself. The address of a byte is the number of bytes we must skip over from the beginning of the file to get to it the byte. The first byte has address zero and the tenth byte has address nine. In the NDF format, Bytes 9-12 contain the four-byte address of the first data byte in the file. The four-byte address is arranged in the little-endian byte order: the most significant byte is first and the least significant is last, at the highest address.
The data itself starts at the data address, and is divided into messages. Each message has a core made up of four bytes. The first byte is the channel number. The next two bytes are the sixteen-bit sample value, high byte first. The fourth byte is a timestamp or, in the case of clock messages, a firmware version number. Most NDF files contain messages consisting only of the message core. But NDF files recorded from devices such as an Animal Location Tracker (A3032) have a payload in addition to the message core. The length of the payload is written in the NDF metadata. If we are planning to navigate through archives that contain messages with payloads, we must read the metadata string and look for a record of the form
Every byte in the NDF file from the first data byte to the final byte in the file is a message byte. When the Neurorecorder adds data to the file, it simply appends the data to the file. It does not have to change anything in the header or make any other adjustment to the file. There is no value in the header that gives the length of the file. The length of the file is available from the operating system.
Having established the location of the first byte, and the length of the messages, we can read messages into our own program. Now we have to interpret them. When the channel number is zero, the message is a clock message. Clock messages are stored by all SCT data receivers at 128 Hz, which is every 256 periods of a 32.768 kH clock oscillator. Subcutaneous transmitters use micro-power 32.768 kHz oscillators to control their transmission rate, and data receivers use them to generate eight-bit (0-255) timestamp values for each SCT message. But the timestamp value for a clock message is always zero, because the clock message is stored whenever the data receiver's eight-bit timestamp value returns to zero. Instead of recording a redundant zero in the timestamp byte of the clock messages, we store the firmware version of the data receiver. But in all other messages, the timestamp byte contains the timestamp of the moment that the SCT message was received. Thus we know this moment with a precision of ±4 ms.
The content of a clock message is a sixteen-bit counter that increments from one clock message to the next. Every 512 s, this value cycles back to zero. The clock messages are always present in the data, unless the data has been corrupted. A corrupted archive can contain sequences of zeros that we call null messages. Any message for which the first and fourth bytes are zero is a null message, and is a sign of corruption. Do not count these as clock messages.
An SCT data message will contain its channel number, which is 1-14, followed by two bytes of data and a timestamp. An SCT auxiliary message will contain channel number 15, followed by sixteen bits in a particular auxiliary format, and a timestamp. Here is an example of four-byte messages in a data stream, expressed in hexadecimal.
00 46 00 04 04 A5 97 06 08 A0 EB 18 0B A5 F6 20 05 A5 E5 37 03 A7 8F 3C 04 A5 9F 46 08 A0 F8 58 0B A6 12 60 05 A5 DD 77 03 A7 8F 7C 04 A5 B3 86 08 A0 B7 98 0B A5 F7 A0 05 A5 EF B7 03 A7 BF BC 04 A5 DD C6 08 A0 B9 D8 0B A5 FF E0 05 A5 E9 F7 03 A7 A6 FC 00 46 01 04 04 A5 B9 06 08 A0 CB 18 0B A6 0D 20 05 A5 DB 37 03 A7 C7 3C
Each block of four bytes is a message. Those that start with 00 are clock messages. For channel zero, successive messages have a data value that increments. The firmware version of this data recorder is 04, which is an early version of the A3018 firmware. The rest are SCT messages. If we select the two middle bytes in a hex editor, we can read the data value. The first three for the example above are from channels 4, 8, and 12, and their sample values are 4391, 41195, and 42486.
The timestamp values for the SCT channels are relative to channel 0. If a transmitter runs at 512 SPS there will, on average, be 4 messages from each of channels 1-14 in between successive messages from channel 0. Not all channels need be present. If only one transmitter was active then there would only be messages from one channel. The time stamps for successive messages in between channel 0 messages increase monotonically unless the archive has been corrupted. The timestamps of the first three messages are 6, 24, and 32. The timestamps of the message from channel 4 are 6, 70, 134, 198, and 6. The messages arrive from the different channels roughly but not exactly in the same order between successive clock messages, with each channel sending a message roughly 4 times for every clock message, because they are operating at 512 SPS, while the clock is at 128 Hz.
There are three reasons the messages are not exactly in sequence. First, the transmitters deliberately scatter their transmission in time to minimize systematic collisions. Second, some signals may drop out or be corrupted. Third, we may occasionally receive bad messages on a transmitter channel that will appear as glitches in our data unless we reject them. Reconstruction of the signal despite loss of up to 80% is possible, despite the transmission scatter, the collisions, and occasional bad messages. The Neuroplayer applies reconstruction to the data so that we get the highest quality signal. If we want to read the NDF data directly into some other program, we must either do so without reconstruction, or we must implement reconstruction ourselves.
The code that performs reconstruction for the Neuroplayer is lwdq_sct_recorder in electronics.pas. The comments at the top of the routine and within the routine describe the details of signal reconstruction. In summary: we extract all message from a particular channel in a playback interval, use our knowledge of the nominal sample rate to find the nominal sample times for the signal, and so compose a sequence of time windows in which legitimate samples could have been generated. Samples outside these windows we reject. Within a window, if we have more than one sample, we choose the one most similar to the previous reliable sample. If we have no sample in a window, we insert the value of the previous sample into the reconstructed data. We end up with a complete set of samples for the interval.
Here we list changes in recent versions that will be most noticeable to the user. Earlier changes are here. The Neuroplayer source code is the file Neuroplayer.tcl bundled with the LWDAQ distribution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}